
GPU与RAPIDS中CPU内存的使用
GPU与RAPIDS中CPU内存的使用
提问于 2022-09-19 11:11:01
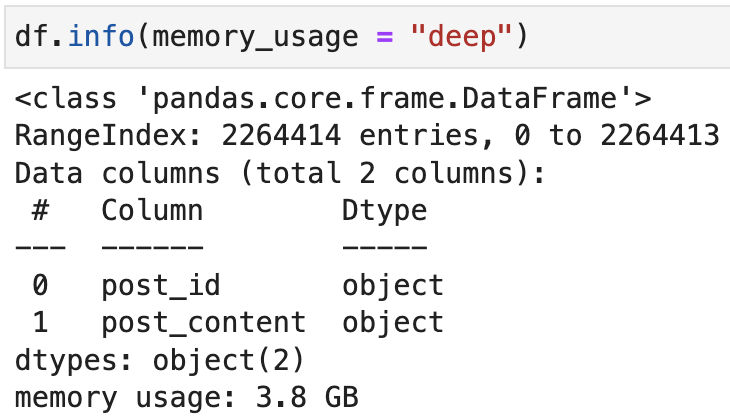
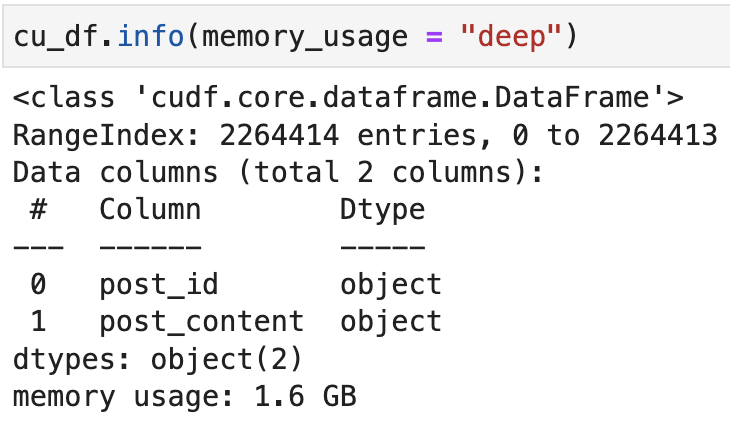
我知道GPU和CPU都有自己的内存,但我不明白的是,为什么在熊猫和急流cuDF中加载相同的数据帧时,内存的使用会有很大的不同。有人能解释一下吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-09-20 19:39:34
正如Josh Friedlander的注释中所指出的,在cuDF中,对象数据类型显式地用于字符串。在熊猫中,这是字符串的数据类型,也是任意/混合数据类型(如列表、切分、数组等)。这可以在许多情况下解释这种内存行为,但如果两列都是字符串,则不能解释。
假设两列都是字符串,则仍然可能存在差异。在cuDF中,字符串列表示为原始字符的单个内存分配、处理缺失值的关联空掩码分配和处理行偏移量的关联分配,这与Apache内存规范一致。因此,很可能这些列中表示的内容在cuDF中的数据结构中比Pandas中的默认字符串数据结构更有效(这在本质上一直都是正确的)。
以下示例可能会有所帮助:
import cudf
import pandas as pd
Xc = cudf.datasets.randomdata(nrows=1000, dtypes={"id": int, "x": int, "y": int})
Xp = Xc.to_pandas()
print(Xp.astype("object").memory_usage(deep=True), "\n")
print(Xc.astype("object").memory_usage(deep=True), "\n")
print(Xp.astype("string[pyarrow]").memory_usage(deep=True))
Index 128
id 36000
x 36000
y 36000
dtype: int64
id 7487
x 7502
y 7513
Index 0
dtype: int64
Index 128
id 7483
x 7498
y 7509
dtype: int64在熊猫中使用Arrow规范字符串dtype可以节省相当多的内存,并且通常与cuDF匹配。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73772464
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号