
9种分位数的虚拟例子
9种分位数的虚拟例子
提问于 2022-09-13 09:27:59
我们都知道R软件有9种通过函数分位数(x,probs,type=1,2,3,4.)计算分位数的方法。
我正在为我的学生寻找一个简单而愚蠢的特别例子,每种类型的分位数计算方法都会返回一个不同的值,样本大小至少为20个值。
最好的例子是,它们都返回了分数0.5 (即中位数)的不同值。
我试图模拟一些随机向量,但我无法同时得到给定分位数的所有变量的不同值。
谢谢你的帮助。
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-09-13 11:13:27
看看在纸中引用的?quantile。
在定义的基础上,type = 1,3,4对probs = 0.5总是给出相同的结果,type = 2,5,6,7,8,9对probs = 0.5总是给出相同的结果。在一阶或最后一阶统计量附近最容易看到这些差异:
quantile.vec <- Vectorize(function(x, probs, type) quantile(x, probs, type = type), "type")
quantile.vec(1:4, c(0.25, 0.3, 0.5), 1:9)
#> [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
#> 25% 1 1.5 1 1.0 1.5 1.25 1.75 1.416667 1.4375
#> 30% 2 2.0 1 1.2 1.7 1.50 1.90 1.633333 1.6500
#> 50% 2 2.5 2 2.0 2.5 2.50 2.50 2.500000 2.5000
quantile.vec(1:20, c(0.05, 0.06, 0.5), 1:9)
#> [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
#> 5% 1 1.5 1 1.0 1.5 1.05 1.95 1.350000 1.3875
#> 6% 2 2.0 1 1.2 1.7 1.26 2.14 1.553333 1.5900
#> 50% 10 10.5 10 10.0 10.5 10.50 10.50 10.500000 10.5000这两个情节可能有用。
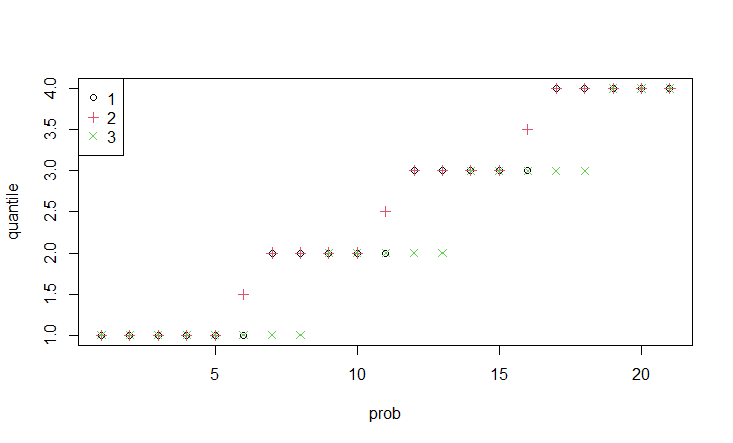
matplot(quantile.vec(1:4, seq(0, 1, 0.05), 1:3), type = "p", pch = c(1, 3:4), col = 1:3, xlab = "prob", ylab = "quantile")
legend("topleft", legend = 1:3, pch = c(1, 3:4), col = 1:3)
matplot(quantile.vec(1:4, seq(0, 1, 0.05), 4:9), type = "p", pch = 0:6, col = 1:6, xlab = "prob", ylab = "quantile")
legend("topleft", legend = 4:9, pch = 0:6, col = 1:6)
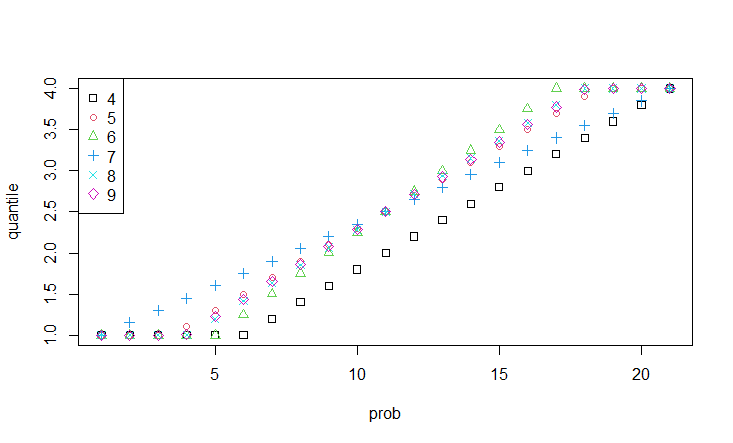
类型8和9之间的差别很小。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73700564
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号