
无法在DBFS中保存文件
无法在DBFS中保存文件
提问于 2022-09-13 09:13:40
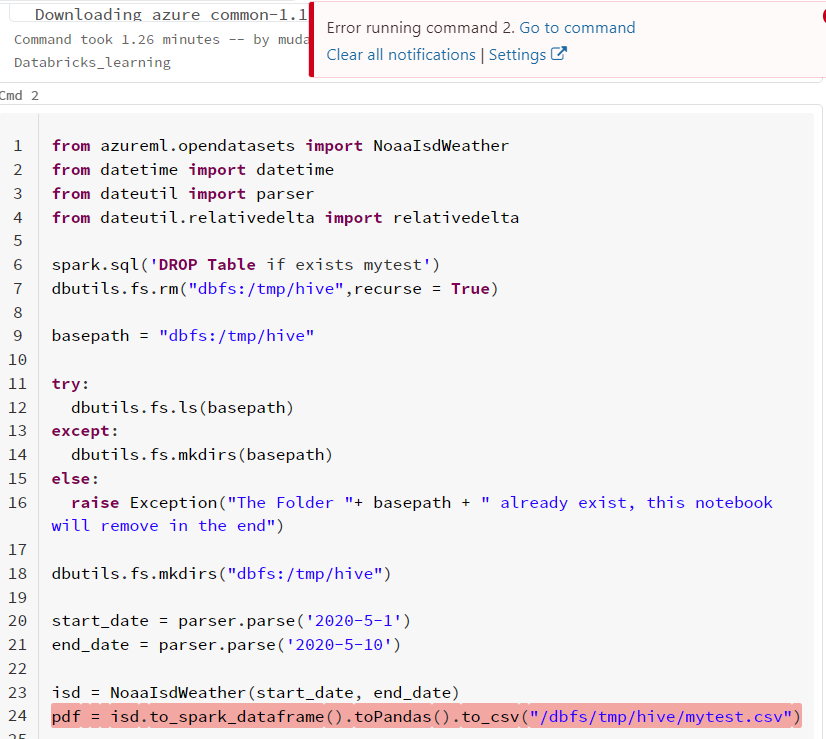
我已经采取了蔚蓝的数据集,可供实践。我从那个数据集中得到了10天的数据,现在我想以csv格式将这些数据保存到DBFS中。我面临一个错误:
“没有这样的文件或目录:'/dbfs/temp/hive/mytest.csv'”
但另一方面,如果我能够直接从DBFS访问路径。这条路是正确的。
我的代码:
from azureml.opendatasets import NoaaIsdWeather
from datetime import datetime
from dateutil import parser
from dateutil.relativedelta import relativedelta
spark.sql('DROP Table if exists mytest')
dbutils.fs.rm("dbfs:/tmp/hive",recurse = True)
basepath = "dbfs:/tmp/hive"
try:
dbutils.fs.ls(basepath)
except:
dbutils.fs.mkdirs(basepath)
else:
raise Exception("The Folder "+ basepath + " already exist, this notebook will remove in the end")
dbutils.fs.mkdirs("dbfs:/tmp/hive")
start_date = parser.parse('2020-5-1')
end_date = parser.parse('2020-5-10')
isd = NoaaIsdWeather(start_date, end_date)
pdf = isd.to_spark_dataframe().toPandas().to_csv("/dbfs/temp/hive/mytest.csv")我该怎么办?
谢谢
回答 1
Stack Overflow用户
发布于 2022-09-13 09:59:59
我试着复制同样的问题。首先,我使用了以下代码,并确保该目录使用os.listdir()存在。
from azureml.opendatasets import NoaaIsdWeather
from datetime import datetime
from dateutil import parser
from dateutil.relativedelta import relativedelta
spark.sql('DROP Table if exists mytest')
dbutils.fs.rm("dbfs:/tmp/hive",recurse = True)
basepath = "dbfs:/tmp/hive"
try:
dbutils.fs.ls(basepath)
except:
dbutils.fs.mkdirs(basepath)
else:
raise Exception("The Folder "+ basepath + " already exist, this notebook will remove in the end")
dbutils.fs.mkdirs("dbfs:/tmp/hive")
import os
os.listdir("/dbfs/tmp/hive/")

然后,使用
- 使用
to_pandas_dataframe()编写csv。这成功地将所需的数据写入所需路径中的csv文件.
。
mydf = isd.to_pandas_dataframe()
mydf.to_csv("/dbfs/tmp/hive/mytest.csv")页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73700388
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号