
Python抓取: soup.select的问题
Python抓取: soup.select的问题
提问于 2022-09-13 02:32:43
我正在开发一个python脚本,用于从特定站点( https://finance.yahoo.com/quote/AUDUSD%3DX/history?p=AUDUSD%3DX )中刮取数据
我在用BeautifulSoup。这一页上有趣的数据如下:
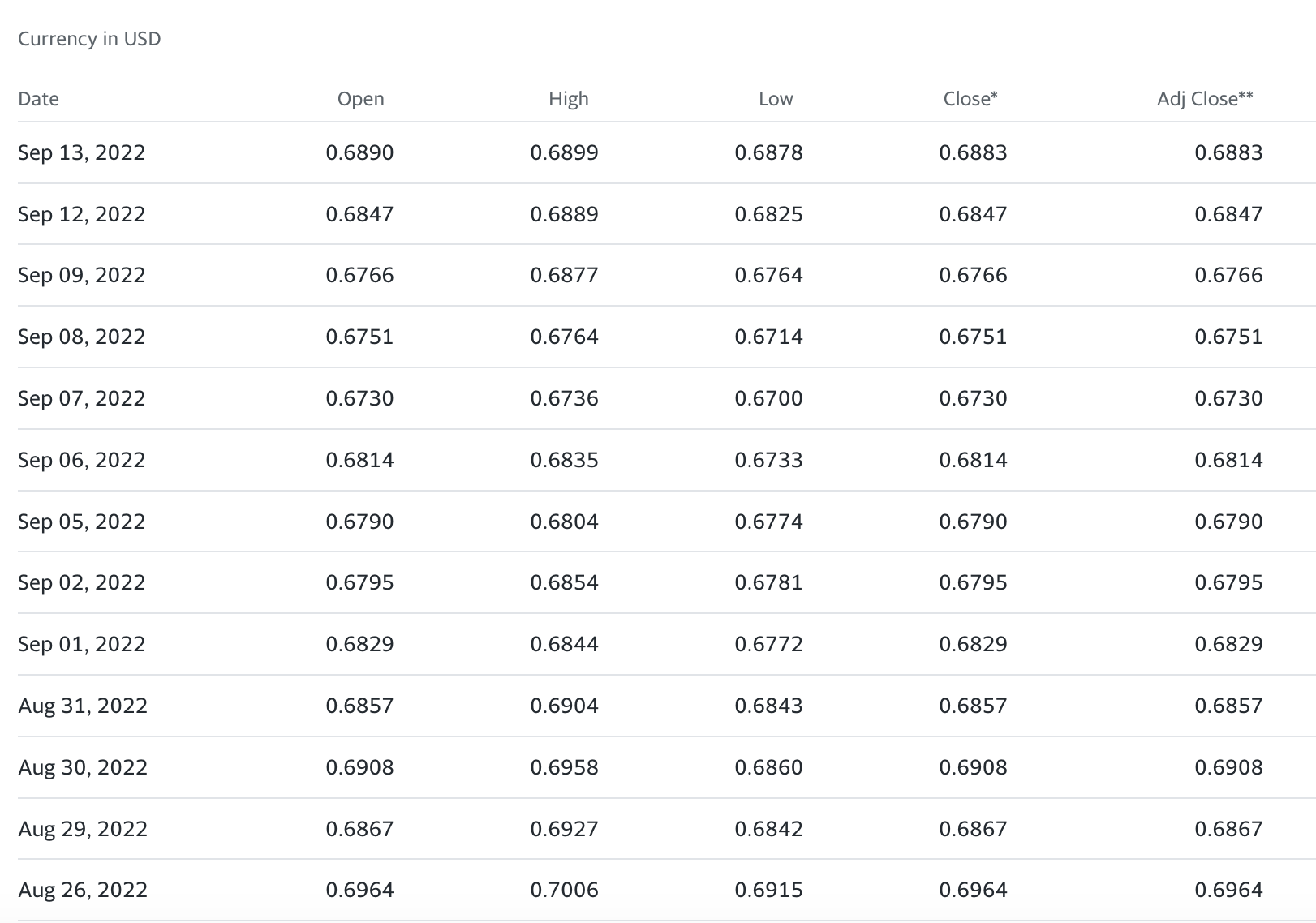
这次我使用soup.select方法,类名为W(100%) M(0),我的代码如下所示:
import requests
import pandas as pd
from bs4 import BeautifulSoup
url = "https://finance.yahoo.com/quote/AUDUSD%3DX/history?p=AUDUSD%3DX"
soup = BeautifulSoup(requests.get(url).content, "html.parser")
table = soup.select(table:has(-soup-contains("W(100%) M(0)")))
print(table)这并不能产生我想要的结果。
我也尝试过这样做:
import requests
import pandas as pd
from bs4 import BeautifulSoup
url = "https://finance.yahoo.com/quote/AUDUSD%3DX/history?p=AUDUSD%3DX"
soup = BeautifulSoup(requests.get(url).content, "html.parser")
table = soup.select("W(100%) M(0)")
print(table)并且存在错误,如下所示
Traceback (most recent call last):
File "/Users/ryanngan/PycharmProjects/Webscraping/seek.py", line 8, in <module>
table = soup.select("W(100%) M(0)")
File "/Users/ryanngan/PycharmProjects/Webscraping/venv/lib/python3.9/site-packages/bs4/element.py", line 1973, in select
results = soupsieve.select(selector, self, namespaces, limit, **kwargs)
File "/Users/ryanngan/PycharmProjects/Webscraping/venv/lib/python3.9/site-packages/soupsieve/__init__.py", line 144, in select
return compile(select, namespaces, flags, **kwargs).select(tag, limit)
File "/Users/ryanngan/PycharmProjects/Webscraping/venv/lib/python3.9/site-packages/soupsieve/__init__.py", line 67, in compile
return cp._cached_css_compile(pattern, ns, cs, flags)
File "/Users/ryanngan/PycharmProjects/Webscraping/venv/lib/python3.9/site-packages/soupsieve/css_parser.py", line 218, in _cached_css_compile
CSSParser(
File "/Users/ryanngan/PycharmProjects/Webscraping/venv/lib/python3.9/site-packages/soupsieve/css_parser.py", line 1159, in process_selectors
return self.parse_selectors(self.selector_iter(self.pattern), index, flags)
File "/Users/ryanngan/PycharmProjects/Webscraping/venv/lib/python3.9/site-packages/soupsieve/css_parser.py", line 985, in parse_selectors
key, m = next(iselector)
File "/Users/ryanngan/PycharmProjects/Webscraping/venv/lib/python3.9/site-packages/soupsieve/css_parser.py", line 1152, in selector_iter
raise SelectorSyntaxError(msg, self.pattern, index)
soupsieve.util.SelectorSyntaxError: Invalid character '(' position 1
line 1:
W(100%) M(0)如何使用soup.select方法刮取上述数据?非常感谢。
回答 1
Stack Overflow用户
发布于 2022-09-13 05:45:32
使用直接类选择器(例如.W(100%))中断,因为它是无效的CSS选择器语法。
但是,您可以使用通过attribute*=partial表示的包含语法来解决这个问题。
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
}
response = requests.get(
"https://finance.yahoo.com/quote/AUDUSD%3DX/history?p=AUDUSD%3DX",
headers=headers
)
# select any element where class contains "W(100%)" and class contains "M(0)":
soup = BeautifulSoup(response.text)
table = soup.select('[class*="W(100%)"][class*="M(0)"]')页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73696975
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号