
熊猫绝对忽略布尔切片?(删除“未使用”类别)
熊猫绝对忽略布尔切片?(删除“未使用”类别)
提问于 2022-09-11 13:17:50
很多时候,我甚至不得不将连续的数据转换成分类的数据类型,因为它有助于我的统计分析。
当我对分类列应用布尔索引(值< 11)时,它们不会像预期的那样被切片:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
### MAKE TESTDATA
df = sns.load_dataset("fmri")
df["timepoint"] = pd.Categorical(df["timepoint"], ordered=True)
### PERFORM BOOLEAN SLICING
df = df.loc[df["timepoint"] < 11]
# df = df.where(df["timepoint"] < 11) # SAME RESULT
g = sns.catplot(data=df, y="signal", x="timepoint")这会产生不正确的情节。X轴仍然超过11,而数据点被正确地切分:
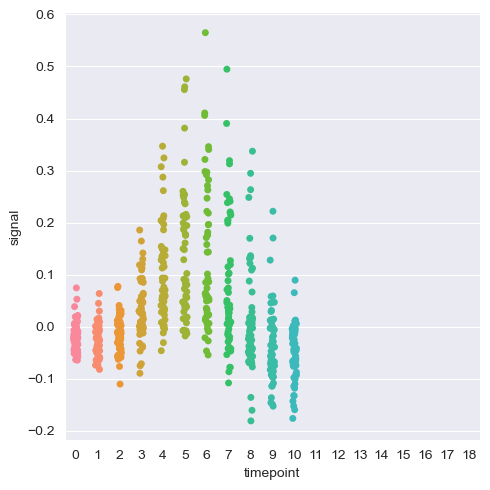
原因:
分类数据被切片,但是它的索引(“类别”)忽略了切片操作。熊猫似乎用这个指数来显示x轴。
>>> print(df.timepoint.cat.categories)
Int64Index([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18], dtype='int64')是什么让它发挥作用的:
在转换为分类之前执行切片会导致所需的行为。同样,将分类类型转换为数字类型,然后再转换为范畴类型也是如此。不过。我怀疑他们的意图是这样的。
问题:
是否有一种优雅的方法可以通过分类列删除“未使用”类别(而不来回更改数据类型)?
回答 1
Stack Overflow用户
发布于 2022-09-11 13:17:50
熊猫有意保留“未使用”类别。你可以用
df["timepoint"] = df["timepoint"].cat.remove_unused_categories()页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73679590
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号