
高精度和正确评估但错误预测的CNN模型
高精度和正确评估但错误预测的CNN模型
提问于 2022-09-10 12:24:49
我正在研究一个肿瘤分类问题,我有4类胶质瘤(1624例)、脑膜瘤(1645例)、结节(2000例)和垂体(1757例)。我保存的模型有问题,当我这样做的时候,混乱矩阵显示出几乎完美的结果--没有偏见或任何东西。
model.evaluate(test_set)我得到: categorical_accuracy: 0.9872,0.06456023454666138,0.9871976971626282
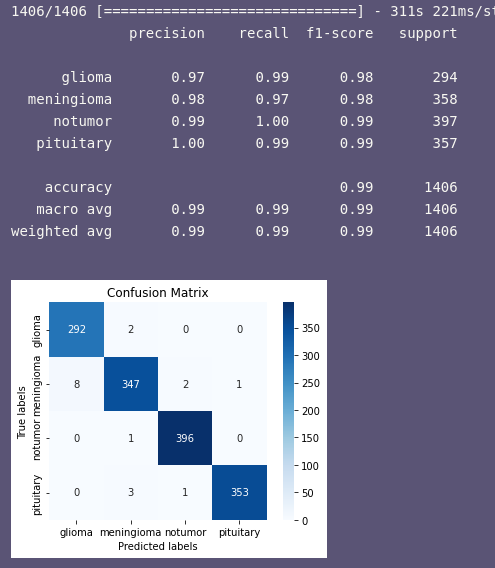
但是,当我尝试做预测时,所有的结果都是错误的(即使我有意为模型注入训练数据来预测),我也为预测编写了这个函数:
def predict_on_one_image(model,image_path):
img = imread(image_path)
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
img = np.expand_dims(np.stack((img,)*3, axis=-1), axis=0).astype(np.float32)
p = model6.predict(img)
return {'class':p.argmax(axis=-1)[0],'probability':p}我的标签是:
{'glioma': 0, 'meningioma': 1, 'notumor': 2, 'pituitary': 3}如果我试图从训练集中预测出图像的类别,原始类别=胶质瘤
predict_on_one_image(model6,'path_here/training/glioma/Te-gl_0016.jpg' )我得到的等级预测是新的
{'class': 2, 'probability': array([[0., 0., 1., 0.]], dtype=float32)}我怀疑它是否偏重于无瘤,因为它有最多的数据(类不平衡问题),但无论如何,我是否可以得到正确的预测,而不必再次运行模型?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-09-10 13:03:41
基本上,我需要处理用于预测的图像,就像我处理它们以进行培训一样(我使用ImageDataGenerator重新标定了它们)。
我添加了这几行代码,它可以正确地预测:
img = imread('path_here/testing/notumor/Te-no_0164.jpg')
x = asarray(img)
x = x / 255.
x = np.expand_dims(x, axis=0)
images = np.vstack([x])
classes = model6.predict(images, batch_size=10)
print('Predicted class is :')
print(np.argmax(classes))贷记:This comment
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73671801
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号