
R中一个变量相隔几行的两个值的有效比较
我正在使用RVersion4.2.1,我有一个工作解决方案来实现我想要实现的目标(见下文)。然而,它效率极低,只生成一个变量就会运行4天。因此,我正在寻找一种更有效的方法来实现我想要的结果。
数据与问题描述
我在data.table中对700多家公司的几个时间段进行了大约50万次观察。我的数据由firm_id、period和destination唯一标识。我对感兴趣的是,这些公司是否以及何时开始在特定的目的地开展业务。我知道一家公司是在哪个时期经营的。该信息是通过将destination与另一个已经存在的名为destination_presence的变量组合而提供的。destination_presence存储为numeric,并提供关于一家公司是否在destination声明的目的地运营的信息。destination_presence可以是NA,1(=公司在各自的目的地操作),也可以是0(公司不在各自的目的地操作)。destination是一个66个级别的factor (例如,"usa“、"canada”、.)这就是为什么每一个firm_id-period-combination在数据集中有66个观测。
我的新变量internationalization可以是NA,1(=公司在当前期间在各自的目的地开始操作),0(公司在当前期间没有在各自的目的地开始操作)。因此,internationalization == 1只有在公司在特定目的地启动操作时才会发生。请注意,这种情况可能发生不止一次,例如,一家公司可以在第2期在目的地D开始营业,在第4期离开目的地D,在第9期再次输入目的地D。
下面是一个简短的数据示例:
数据示例
#load packages
library(data.table)
dt <- as.data.table(
structure(list(
firm_id = structure(as.factor(c(rep("f1", 18), rep("f2", 18), rep("f3", 18), rep("f4", 18)))),
period = structure(as.factor(c(rep("3", 6), rep("5", 6), rep("6", 6), rep("1", 6), rep("2", 6), rep("3", 6), rep("0", 6), rep("1", 6), rep("2", 6), rep("7", 6), rep("8", 6), rep("9", 6)))),
min_period = structure(c(rep(3, 18), rep(1, 18), rep(0, 18), rep(7, 18))),
destination = structure(as.factor(c("usa", "chile", "austria", "kenya", "china", "new zealand", "usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand"))),
destination_presence = structure(c(rep(NA, 6), 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, rep(NA, 6), 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1,0, 0, 1, 1, 1, 1, rep(NA, 6)), class = "numeric")),
.Names = c("firm_id", "period", "min_period", "destination", "destination_presence" ), row.names = c(NA, 5), class = "data.table"))电流逼近
# load packages
library(data.table)
# order data by firm_id, period, and destination to make sure that all data are similarly ordered
dt <-
dt[with(dt, order(firm_id, period, destination)), ]
# Step 1: fill first variable for minimum periods as in these cases there is no prior period with which to compare
dt[, internationalization := ifelse(
period == min_period & # min_period is the minimum period for a specific firm
destination_presence == 1,
1,
NA
)]
# show internationalization variable output
summary(as.factor(dt$internationalization))
# Step 2:
# there are 6 rows for every firm_id-period combination because there are 6 different levels in the factor variable destination (i.e., 6 different countries) in the example data set
# hence, for the first 6 rows there are no prior ones to compare with. therefore, start in row 7
for (i in 7:nrow(dt)) {
print(i) # print i to know about progress of loop
dt$internationalization[i] <-
# a) if there is already a value in internationalization, keep this value (output from Step 1)
ifelse(
!is.na(dt$internationalization[i]),
dt$internationalization[i],
# b) if there is no information on the international operation destinations of a firm in the current period, insert NA in internationalization
ifelse(
is.na(dt$destination_presence[i]),
NA,
# c) if in prior period (i-6 because of 6 country levels per firm_id-period entry) there are no information on destination presence, treat observations as first internationalization
ifelse(
is.na(dt$destination_presence[i - 6]) & dt$firm_id[i] == dt$firm_id[i - 6],
dt$destination_presence[i],
# c) if in last period (i - 6) a specific firm was not operating at a specific destination (dt$destination_presence[i - 6] != 1) and is operating at this specific destination in the current period (dt$destination_presence[i] == 1), set internationalization == 1
ifelse(
(dt$destination_presence[i] == 1) & (dt$destination_presence[i - 6] != 1) & (dt$firm_id[i] == dt$firm_id[i - 6]),
1,
0
)
)
)
)
}期望结果
这应该与上述方法的结果相匹配。
# desired outcome
desired_dt <- as.data.table(
structure(list(
firm_id = structure(as.factor(c(rep("f1", 18), rep("f2", 18), rep("f3", 18), rep("f4", 18)))),
period = structure(as.factor(c(rep("3", 6), rep("5", 6), rep("6", 6), rep("1", 6), rep("2", 6), rep("3", 6), rep("0", 6), rep("1", 6), rep("2", 6), rep("7", 6), rep("8", 6), rep("9", 6)))),
min_period = structure(c(rep(3, 18), rep(1, 18), rep(0, 18), rep(7, 18))),
destination = structure(as.factor(c("usa", "chile", "austria", "kenya", "china", "new zealand", "usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand"))),
destination_presence = structure(c(rep(NA, 6), 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, rep(NA, 6), 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1,0, 0, 1, 1, 1, 1, rep(NA, 6)), class = "numeric"),
internationalization = structure(c(rep(NA, 6), 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, rep(NA, 6), rep(0, 5), 1, rep(0,6), 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, rep(NA, 6)))),
.Names = c("firm_id", "period", "min_period", "destination", "destination_presence", "internationalization"), row.names = c(NA, 6), class = "data.table"))期待您对如何使代码更高效的建议!
回答 2
Stack Overflow用户
发布于 2022-09-09 14:08:46
这可以通过使用data.table的setorder和shift函数使用一个链式命令来完成,它将非常快。
setorder(dt, firm_id, destination, period)[, internationalization := destination_presence*(firm_id != shift(firm_id, 1, "") | destination != shift(destination, 1, "") | !pmax(0, shift(destination_presence), na.rm = TRUE))]注意,没有使用min_period。
Stack Overflow用户
发布于 2022-09-09 14:26:54
编辑后,在下面的性能中包含@ below 94代码
for循环是在这里减慢代码速度的罪魁祸首。tidyverse替代选项将有助于加快这一过程。
代码
dt= as.data.frame(dt) #transform your data into a data frame
dt$id = 1:nrow(dt) # Add a unique row id to select them later
dt$period = as.numeric(dt$period) # Change the factor into numeric
#Create an intermediate dataframe only with the data of interest
temp = dt %>% filter(destination_presence == 1) %>%
group_by(firm_id, destination) %>%
mutate(b = ifelse(lag(period)==period-1, 0, 1), #if period are consecutive transform to 0
int = ifelse(is.na(b)|b==1, 1, 0))%>% #the final internationalization variable to be added in the original data frame
select(-b) #remove the useless column
dt$inter = dt$destination_presence # Create the internationalization column based on the destination
dt[temp$id, "inter"] = temp$int # Transfer the column for the identified rows above
dt
firm_id period min_period destination destination_presence internationalization
1: f1 3 3 austria NA NA
2: f1 5 3 austria 0 0
3: f1 6 3 austria 0 0
4: f1 3 3 chile NA NA
5: f1 5 3 chile 0 0
6: f1 6 3 chile 0 0
7: f1 3 3 china NA NA
8: f1 5 3 china 0 0
9: f1 6 3 china 0 0
10: f1 3 3 kenya NA NA
11: f1 5 3 kenya 1 1
12: f1 6 3 kenya 1 0
13: f1 3 3 new zealand NA NA
14: f1 5 3 new zealand 1 1
15: f1 6 3 new zealand 1 0
16: f1 3 3 usa NA NA
17: f1 5 3 usa 0 0性能
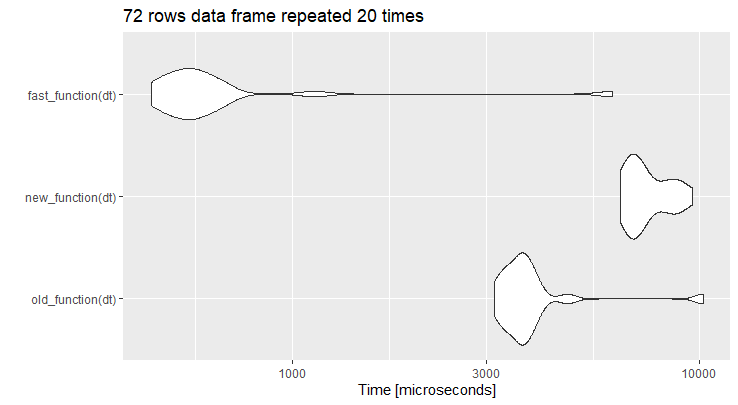
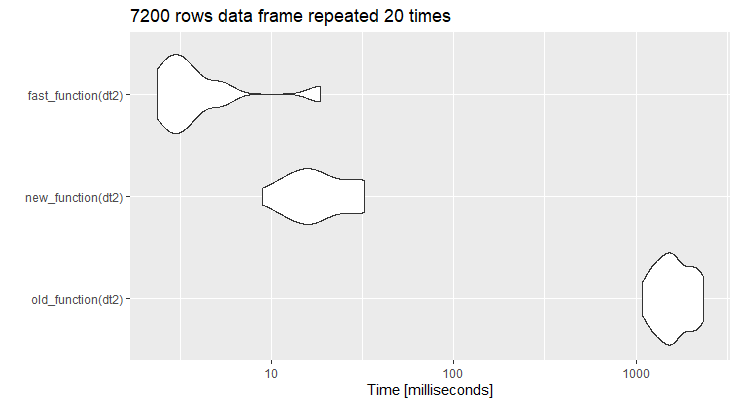
编辑:添加为fast_function的@ Code 94中的代码
我把你的代码扭曲为old_function,代码隐藏为new_function。实际上,在所提供的示例数据框架上运行代码更快。但是,当行数增加时,new_function是非常有效的。
https://stackoverflow.com/questions/73655570
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号