
创建具有两个变量(2D)的密度图,并在同一地块中对两个数据进行叠加,以进行比较
创建具有两个变量(2D)的密度图,并在同一地块中对两个数据进行叠加,以进行比较
提问于 2022-09-03 19:04:53
我有两个类似类型的数据。我希望从R中的每个数据中使用两列(二元)创建密度图,然后将这两个密度图叠加到相同的图上进行比较。另外,我想知道在绘制这些密度图并比较它们之后,我是否能找到平均值、中位数和标准差。例如,我有两个数据文件,如下所示(大得多)。我希望在X中绘制Avg,在Y轴上绘制Dmel_pl,并为第一个dataframe df1创建一个密度图。然后,通过将Avy放在X中,将Dpse_pl放在Y轴上,对第二个数据帧重复相同的操作。为了比较这两个密度图,我想要在相同的图中创建它们并覆盖它们。同时,从这两个密度图中,我要计算出平均值、中位数、std值和其他常用的统计指标来比较密度图,并使它们之间有一个相关性。这是数据帧1的代码:
df1 <- data.frame (Avg = c(19,15,25,16,1.5,23,10),
Dmel_pl= c(42,58,87.45,93.24,70.34,55.90,56.12))这是第二个数据帧的代码:
df2 <- data.frame (Avg = c(10,13,22,34,8,25),
Dpse_pl= c(67,95.05,49.43,70.34,43.80,57.32))回答 1
Stack Overflow用户
发布于 2022-09-05 02:22:31
以下是实现这一目标的一个选项
首先,可以将所有数据帧合并为一个单独的数据帧:
library(tidyverse)
df3 = df1 %>% full_join(df2, by = "Avg") %>%
pivot_longer(!Avg, names_to = "Pl", values_to = "values") %>%
filter(!is.na(values))然后创建你的情节:
library(ggplot2)
ggplot(df3, aes(x=Avg, y=values, colour = Pl))+
geom_density2d()+
geom_point()+
facet_wrap(~Pl)+
theme_bw()您可以通过删除绘图调用中的facet_wrap行来覆盖这两个组
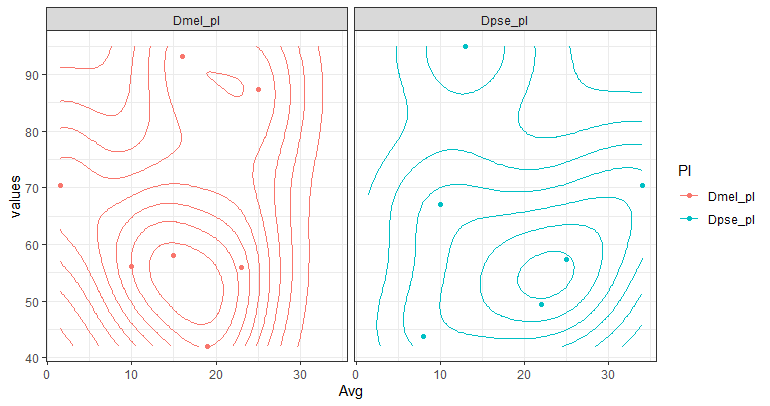
最后,经典统计数据的一个选项是来自describeBy包的psych函数。
library(psych)
describeBy(df3$values, group=df3$Pl)
Descriptive statistics by group
group: Dmel_pl
vars n mean sd median trimmed mad min max range skew kurtosis se
X1 1 7 66.15 18.53 58 66.15 18.3 42 93.24 51.24 0.29 -1.65 7
---------------------------------------------------------------------------------------------------
group: Dpse_pl
vars n mean sd median trimmed mad min max range skew kurtosis se
X1 1 6 63.82 18.32 62.16 63.82 15.5 43.8 95.05 51.25 0.53 -1.29 7.48页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73594815
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号