
用sjPlot (r)重新排序sjPlot中的森林模型变量
我有一组模型,我正在使用来自plot_models包的sjPlot函数在R中一起绘图。这些模型正在绘制使用不同数据集的类似felm回归的置信区间。所有模型都有相同的感兴趣变量,它们的置信区间都是相同的。我已经成功地绘制了所有的模型,但是,我现在无法命令它们如何才是理想的。
我的代码如下:
placebo_models <- paste0("outcome", 1:13, " ~ Variable1 + Variable2 | fe_variable |0| fe_variable") |> lapply(\(x) felm(as.formula(x), data = df))
models_list <- list(placebo_models[[13]], placebo_models[[12]], placebo_models[[11]], placebo_models[[10]], placebo_models[[9]], placebo_models[[8]], placebo_models[[7]], placebo_models[[6]], placebo_models[[5]], placebo_models[[4]], placebo_models[[3]], placebo_models[[2]], placebo_models[[1]])
testplot <- plot_models(models_list, colors = c("RED"), show.values = TRUE, p.threshold = 0.05, spacing = 0.8, dot.size = 1, digits = 5, title = "Placebo Models", axis.labels = c("Variable1", "Variable2")) + scale_color_discrete(labels = c("m1", "m2", "m3", "m4", "m5", "m6", "m7", "m8", "m9", "m10", "m11", "m12", "m13"))我当前的绘图输出如下:
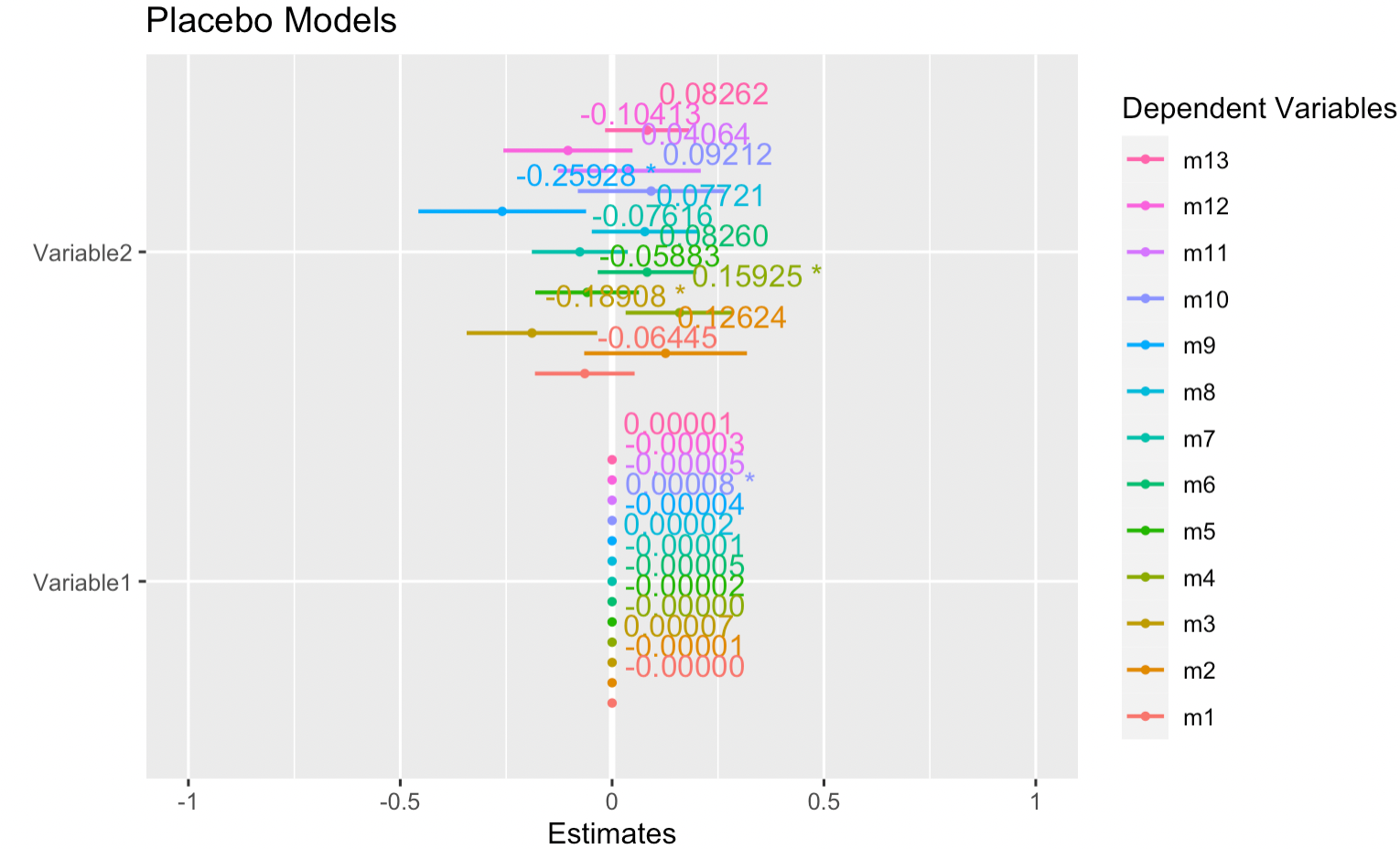
理想情况下,我想改变这个模型,在进入m2 (Variable1,然后是Variable2),m3 (Variable1,然后Variable2)之前,按顺序(从顶部降下来)报告M1的变量1置信区间,然后是M1的变量2置信区间。
是否有一种方法来重新排序所绘制的线条,以便这是可能的?所有模型中的变量都是相同的,所以只要可以重新构造,它就应该适合。不同模型的变量是否能像这样在同一块图中被重新排序和相互混合?
不幸的是,我无法共享原始数据,但是这种可视化应该可以解释这个问题。非常感谢!
回答 1
Stack Overflow用户
发布于 2022-09-05 16:54:09
元素出现在图例中的顺序是基于您将元素提供给plot_models的顺序。Y轴出现的顺序是它们放置在第一个模型中的顺序。
看看这个。这是sjPlot::plot_models()发布的示例。首先,如“帮助”中所示,然后如何更改图例项或绘图项的顺序。至于y轴,重新排列它的能力可能会受到模型的影响。您可以在不改变结果的情况下重新排列在许多回归模型中调用自变量的顺序。我在这里运行了几个检查,以表明这个lm不受变量顺序的影响。
library(sjPlot)
data(efc)
# fit three models
fit1 <- lm(barthtot ~ c160age + c12hour + c161sex + c172code,
data = efc)
fit2 <- lm(neg_c_7 ~ c160age + c12hour + c161sex + c172code,
data = efc)
fit3 <- lm(tot_sc_e ~ c160age + c12hour + c161sex + c172code,
data = efc)
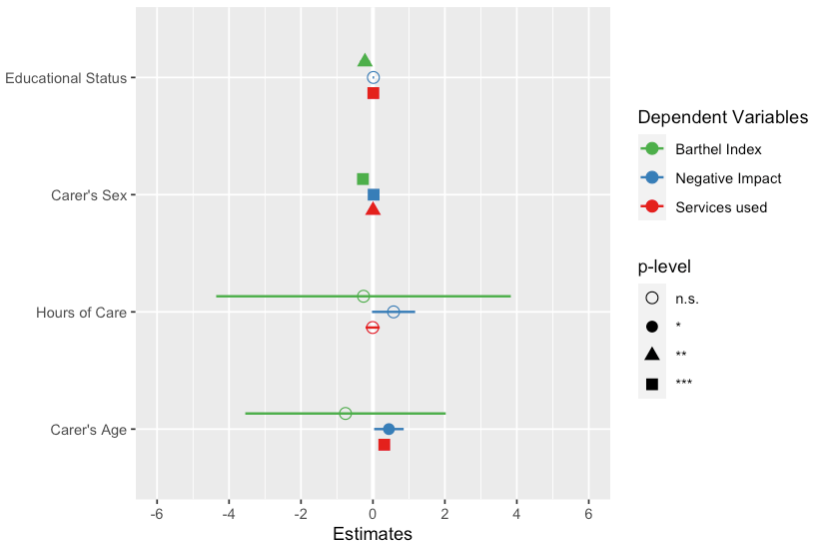
# plot multiple models
plot_models(fit1, fit2, fit3, grid = TRUE)
# plot multiple models with legend labels and
# point shapes instead of value labels
plot_models(
fit1, fit2, fit3,
axis.labels = c(
"Carer's Age", "Hours of Care", "Carer's Sex",
"Educational Status"
),
m.labels = c("Barthel Index", "Negative Impact",
"Services used"),
show.values = FALSE, show.p = FALSE, p.shape = TRUE
)
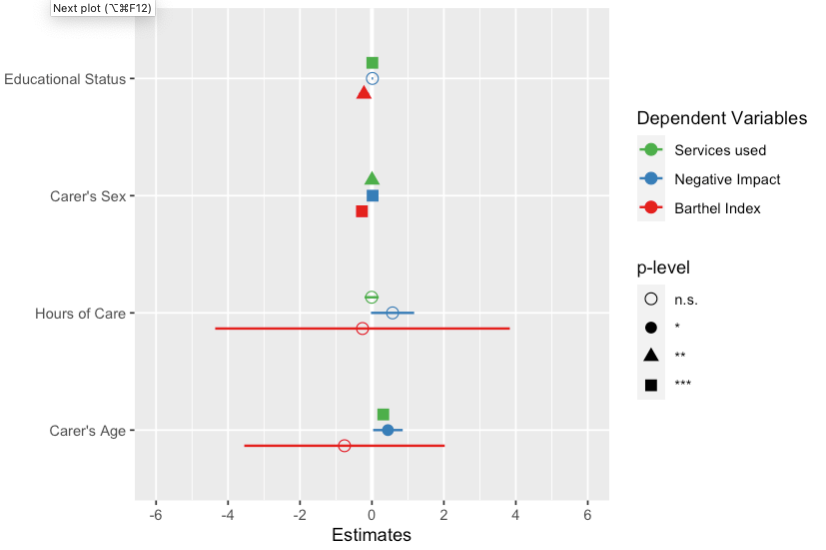
如果我想重新排列传奇Dependent Variables,我需要重新排序调用中的情节。所以我会参考模型订单。标签必须与情节顺序相同。
plot_models(
fit3, fit2, fit1,
axis.labels = c(
"Carer's Age", "Hours of Care", "Carer's Sex",
"Educational Status"
),
m.labels = rev("Barthel Index", "Negative Impact",
"Services used"),
show.values = FALSE, show.p = FALSE, p.shape = TRUE
)
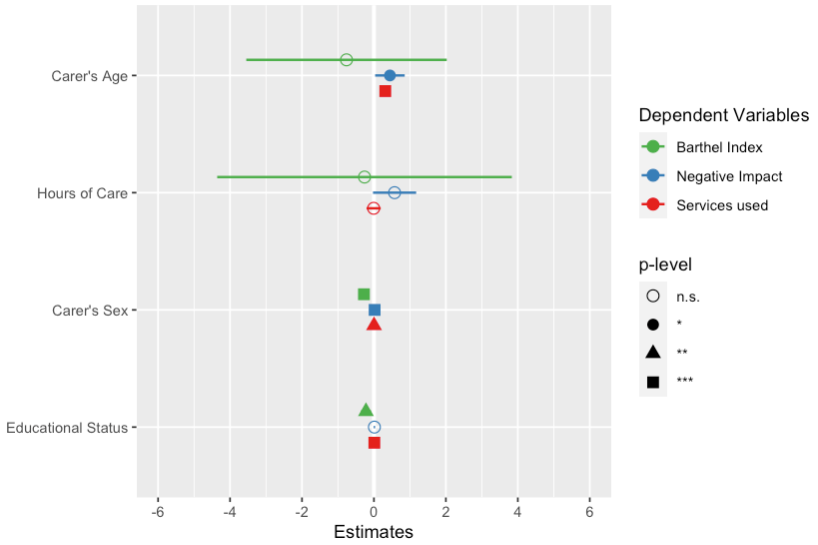
接下来,我重新安排了对fit1的调用,并返回到最初的绘图顺序,您将看到这个图在y轴上有一个不同的顺序,但是这个图例与第一个图中的图例相匹配。
fit1a <- lm(barthtot ~ c172code + c161sex + c12hour + c160age,
data = efc)
plot_models(
fit1a, fit2, fit3,
axis.labels = rev(c(
"Carer's Age", "Hours of Care", "Carer's Sex",
"Educational Status")),
m.labels = c("Barthel Index", "Negative Impact",
"Services used"),
show.values = FALSE, show.p = FALSE, p.shape = TRUE
)
# validate models are identical with R2 and Fstat
summary(fit1)[[8]] # [1] 0.2695598
summary(fit1a)[[8]] # [1] 0.2695598
summary(fit1)[[10]][1] # value # 75.28364
summary(fit1a)[[10]][1] # value # 75.28364
https://stackoverflow.com/questions/73549402
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号