
熊猫同列同组值的分类方法
熊猫同列同组值的分类方法
提问于 2022-08-27 16:04:21
我有一张列有超市顾客购买情况的表格,最多购买的产品是11件,最小的是1件。
每一行代表一个独特的客户:
data.head(9)
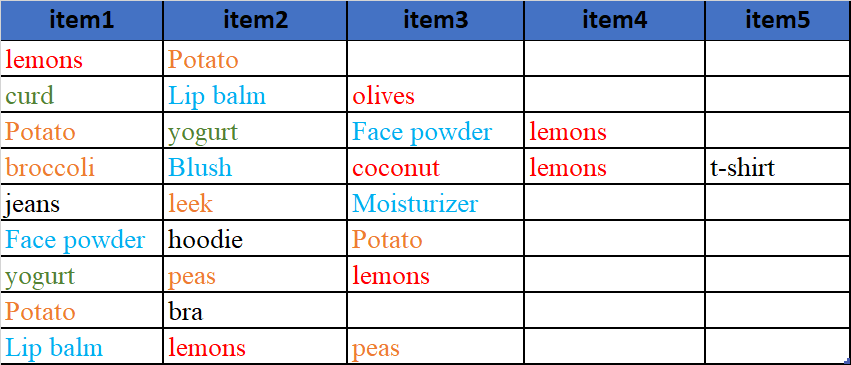
我想根据他们的组(类型)对购买的产品进行分组,以便对每一组进行独立分析。例如,我想将水果产品分组在第1栏中,蔬菜产品在第2栏...etc中。
例如,第二个客户不购买蔬菜,因此在输出中,蔬菜单元格是空的。但是他买了唇膏(这是一种化妆品),所以在产量上,它会放在化妆品栏里。
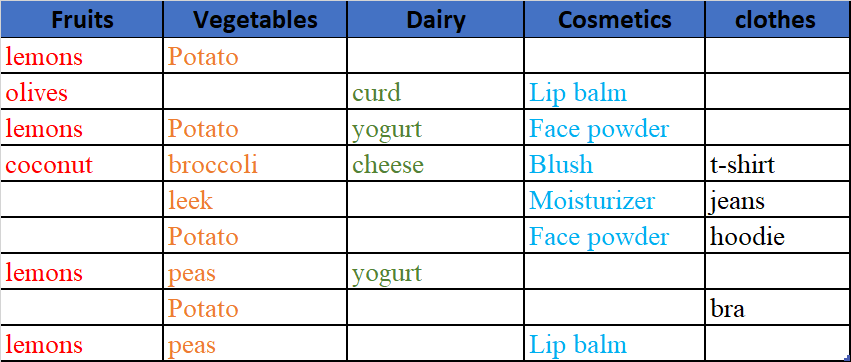
这个表是第一个表的输出,我使用颜色来区分产品组(产品类型)。我想要这样的产出:
output.head(9)
我有另一个表,其中包含组及其所有可能的值:
groups.head()
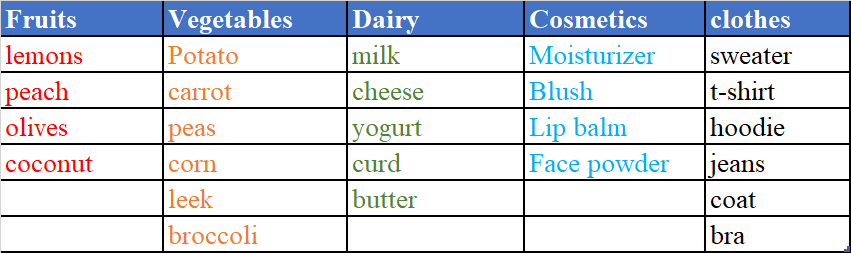
注:每个客户只从同一组购买一种产品。
如何在python dataframe中做到这一点?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-08-28 15:35:28
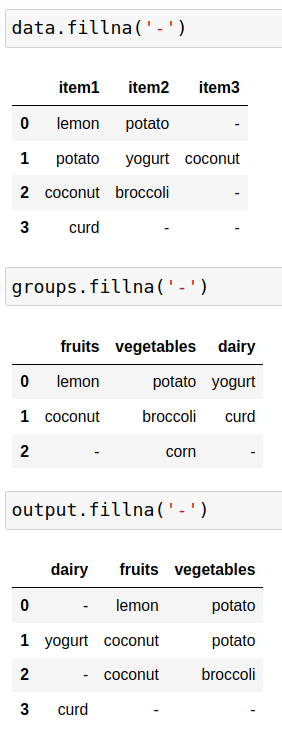
import pandas as pd
from io import StringIO
data = '''
item1,item2,item3
lemon,potato,
potato,yogurt,coconut
coconut,broccoli,
curd,,
'''
data = pd.read_csv(StringIO(data))
groups = '''
fruits,vegetables,dairy
lemon,potato,yogurt
coconut,broccoli,curd
,corn,
'''
groups = pd.read_csv(StringIO(groups))
groups = (
groups
.melt(var_name='group',value_name='product')
.dropna()
.set_index('product')
.squeeze()
)
output = data.apply(
lambda row: pd.Series({groups[p]: p for p in row.dropna()}),
axis=1
)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73512504
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号