
如何从源雪花表将新的增量数据(保存旧记录)插入到三角洲湖表蔚蓝数据库表中
我试图从雪花表逐步插入数据到azure databricks三角洲湖表。
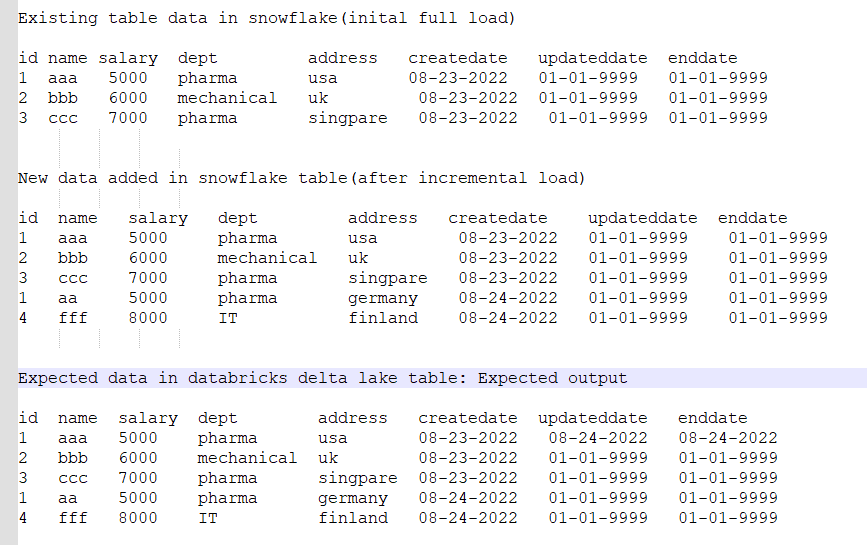
现有表数据
id名称工资部地址创建更新日期截止日期
1 aaa 5000美国制药08-23-2022 01-01-9999 01-01-9999
2 bbb 6000机械英国08-23-2022 01-01-9999 01-01-9999
3 ccc 7000药典08-23-2022 01-01-9999 01-01-9999
添加到表中的新数据
id名称工资部地址创建更新日期截止日期
1 aa 5000制药德国08-24-2022 01-01-9999 01-01-9999
4 fff 8000 IT芬兰08-24-2022 01-01-9999 01-01-9999
表中的预期数据
id名称工资部地址创建更新日期截止日期
1 aaa 5000美国制药08-23-2022 08-24-2022
2 bbb 6000机械英国08-23-2022 01-01-9999 01-01-9999
3 ccc 7000药典08-23-2022 01-01-9999 01-01-9999
1 aa 5000制药德国08-24-2022 01-01-9999 01-01-9999
4 fff 8000 IT芬兰08-24-2022 01-01-9999 01-01-9999
回答 2
Stack Overflow用户
发布于 2022-08-23 15:26:19
尝试使用MERGE语句,这将更新匹配的行并插入不匹配的行。如果数据作为dataframe存储在内存中,则使用以下方法创建一个临时视图:
snowflakedf.createOrReplaceTempView("<ALIAS>")然后,如果您的表主键是id和名称:
MERGE INTO <EXISTING_TABLE_NAME> AS T1 USING
(
SELECT
id,
name,
salary,
dept,
adress,
createdate,
date_format(from_utc_timestamp(current_timestamp(), "CET"),'yyyy-MM-dd') as updateddate,
date_format(from_utc_timestamp(current_timestamp(), "CET"),'yyyy-MM-dd') as enddate
FROM <ALIAS>
) AS TMP
ON T1.id= TMP.id AND T1.name = TMP.name
WHEN MATCHED THEN UPDATE SET
T1.createdate= TMP.createdate,
T1.updateddate= TMP.updateddate,
T1.enddate= TMP.enddate
WHEN NOT MATCHED THEN
INSERT *有关它如何工作的更多信息,请检查:
https://docs.databricks.com/spark/latest/spark-sql/language-manual/delta-merge-into.html
如果插入更适合您的问题,请尝试如下:
INSERT INTO <EXISTING_TABLE_NAME>
SELECT
id,
name,
salary,
dept,
adress,
createdate,
date_format(from_utc_timestamp(current_timestamp(), "CET"),'yyyy-MM-dd') as updateddate,
date_format(from_utc_timestamp(current_timestamp(), "CET"),'yyyy-MM-dd') as enddate
FROM <ALIAS>Stack Overflow用户
发布于 2022-08-24 04:20:05
您可以使用MERGE将数据增量地从雪花表加载到Databricks三角洲湖泊表。
location.
- Since
- 首先使用使用雪花表数据加载的数据创建视图。
- 现在使用三角洲湖
- 在数据库中创建三角洲湖表(如果不存在)--雪花数据由已经插入的记录组成,您可以提取需要寻址的新记录--一个只有匹配条件的合并语句,以便在条件匹配时更新
updateddate和enddate列。
- 可以直接插入其余的记录,因为需要进行必要的更新。我们需要插入新的数据以及现有的id (其他列的不同值)。这就是我们创建
req_snowflake_df
- You的原因,我们可以使用以下代码进行必要的修改,以加载数据incrementally.
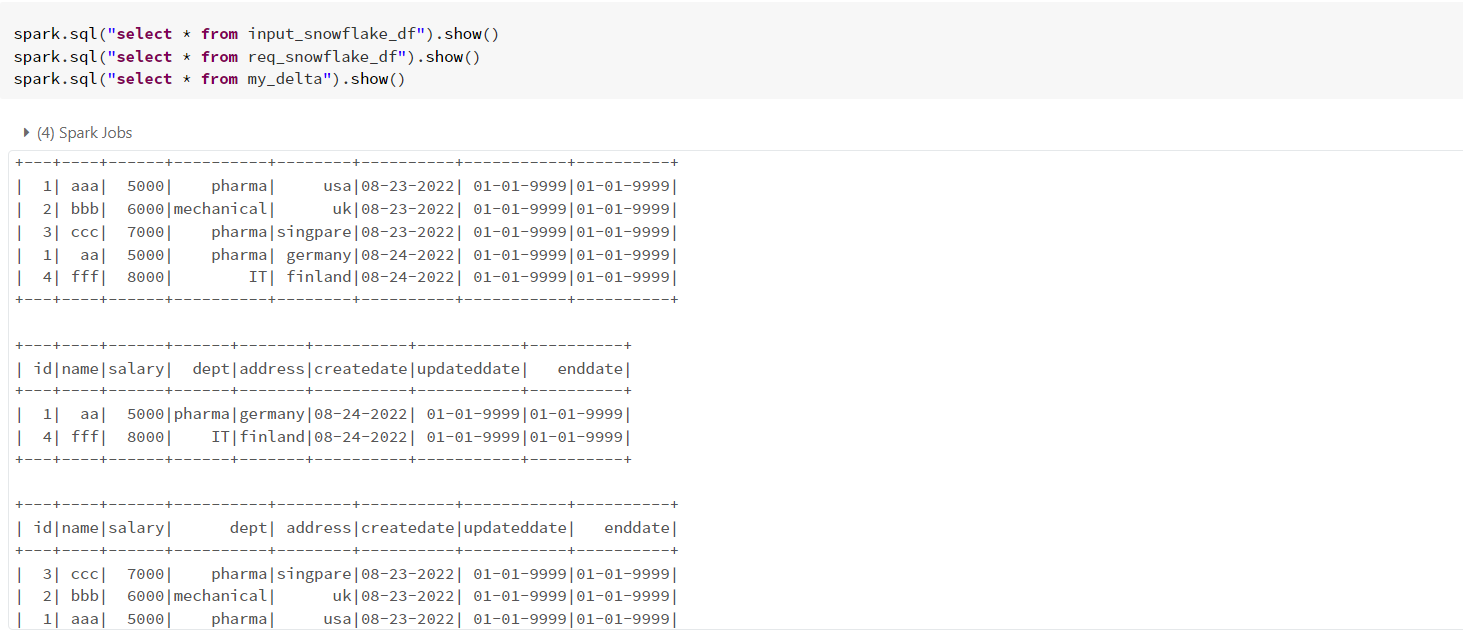
#create view with snowflake table data loaded into dataframe
df.createOrReplaceTempView("input_snowflake_df")
#only new data
df_new_data = spark.sql("select ip.* from input_snowflake_df as ip left join my_delta as d on d.id=ip.id and d.name=ip.name and d.salary=ip.salary and d.address=ip.address and d.createdate=ip.createdate where d.id is NULL")
df_new_data.show()
df_new_data.createOrReplaceTempView("req_snowflake_df")%sql
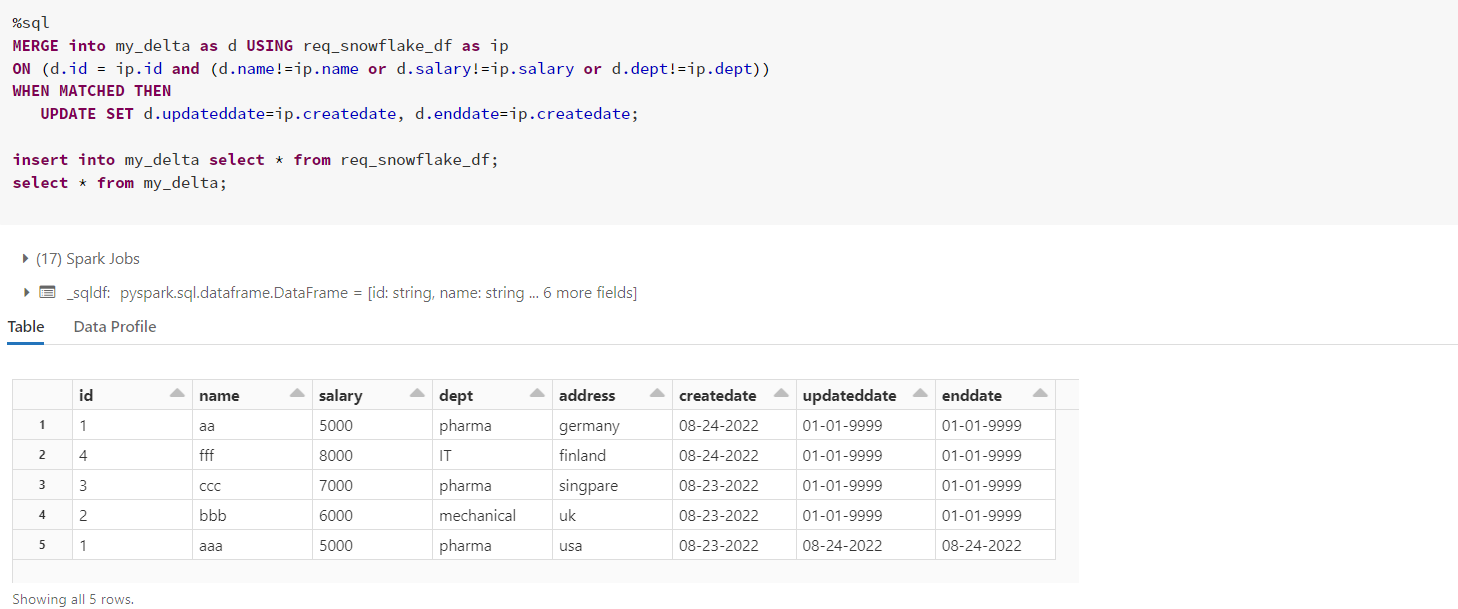
MERGE into my_delta as d USING req_snowflake_df as ip
ON (d.id = ip.id and (d.name!=ip.name or d.salary!=ip.salary or d.dept!=ip.dept))
WHEN MATCHED THEN
UPDATE SET d.updateddate=ip.createdate, d.enddate=ip.createdate;
insert into my_delta select * from req_snowflake_df以下是我的输出图像以供演示:
- 当前雪花表数据,需要新列和我的增量表记录。
合并后的
- :
https://stackoverflow.com/questions/73460646
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号