
如何根据下降的堆栈段高度重新排序R中的百分比叠加条形图?
如何根据下降的堆栈段高度重新排序R中的百分比叠加条形图?
提问于 2022-08-23 11:51:24
我试图在R中排序我的百分比叠加条形图中的条形图,基于下降的堆栈段高度。R会自动按字母顺序对我的分类数据进行排序(包括条形图和它的图例),但我希望对数据进行排序,以便以降序的方式将最大的条形图(具有最大堆栈段高度的条)放在条形图的顶部,最小的条在底部。我不知道如何做到这一点,因为在使用ggplot2之前,我无法用向量手动设置特定的顺序:我的数据集相当大,我需要根据总字段面积(我正在考虑的每个城市的数量变量)来排序。有人知道热能帮我吗?
回答 2
Stack Overflow用户
回答已采纳
发布于 2022-08-23 13:19:46
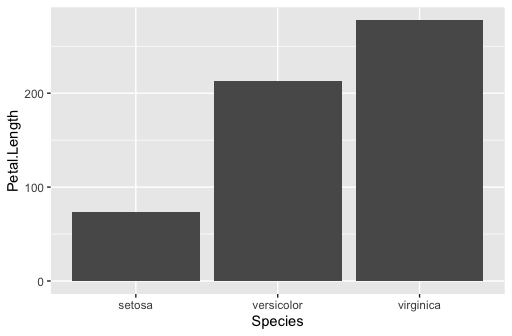
您需要将分类变量设置为有序因子。例如,使用虹膜数据,默认为字母x轴:
iris%>%
ggplot(aes(Species,Petal.Length))+
geom_col()
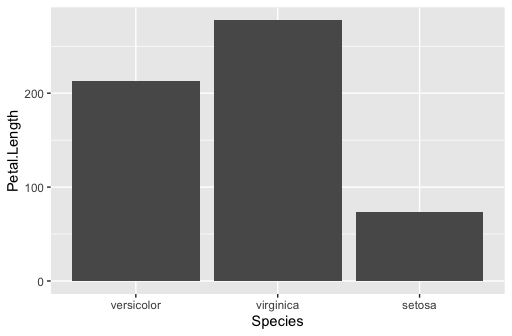
使用fct_reorder (来自预测,包含在tidyverse中),您可以将一个字符变量更改为一个因子,并在一步内给它排序。在这里,我改变了x轴的顺序,也就是按花瓣的平均萼片宽度排序。
iris%>%
mutate(Species=fct_reorder(Species,Sepal.Width,mean))%>%
ggplot(aes(Species,Petal.Length))+
geom_col()
Stack Overflow用户
发布于 2022-08-24 08:28:01
st_des_as %>%
mutate(COLTURA=fct_reorder(COLTURA,tot_area),.desc=F) %>%
ggplot(aes(x=" ", y=tot_area, fill=COLTURA)) +
geom_bar(position= "fill", stat="identity") +
facet_grid(~ZONA) +
labs(x=NULL, y="landcover (%)") +
scale_y_continuous(labels=function(x) paste0(x*100)) +
scale_fill_manual(name="CROP TYPE",values=colours_as) +
theme_classic() +
theme(legend.key.size = unit (10, "pt")) +
theme(legend.title = element_text(face="bold"))
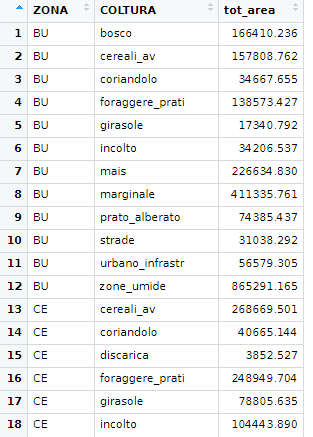
geom_col()以下是我的一些数据,你可以看到,它们是按区域(ZONA)和作物类型(COLTURA)划分的数值。
下面是第一个图:左边的第一个被正确排序,而其他三个则不是按照它们的条高排序,而是按照第一个图的相同排序,而不管它们自己的条的维数。

页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73458217
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号