
查找指定索引之前和之后的值的最近索引。
查找指定索引之前和之后的值的最近索引。
提问于 2022-08-21 11:00:39
我有刺激的数据记录
在这里,我有一个列,其中激光脉冲标记为'1's和一个列,其中心电图峰值标记为'1's。
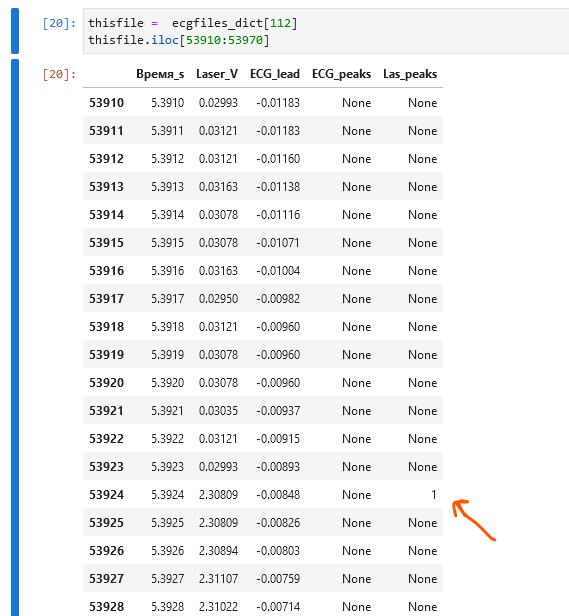
我正努力想出一种有效的方法来找出离激光峰值最近的两个心电图峰--一个在激光峰值之前,另一个在激光峰值之后。
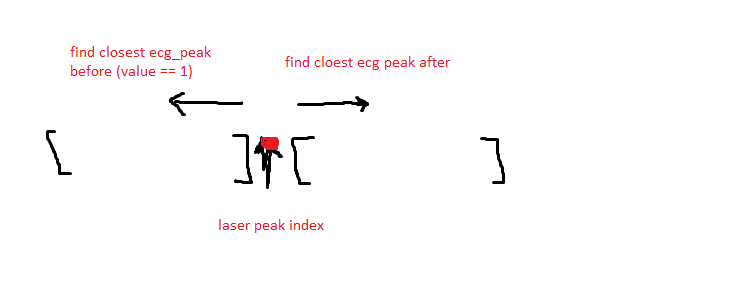
对我来说,最简单的方式似乎是“短暂”循环,但也许有一些熊猫功能可以让它更有效率?
回答 2
Stack Overflow用户
回答已采纳
发布于 2022-08-21 21:52:00
让我们假设您有下面的数据文件来演示:
df = pd.DataFrame({
'ECG_peaks':[None, None, None, None, None, 1, None, None, None, 1, None, None, None, None, 1, None, None, None],
'Las_peaks':[None, None, None, None, None, None, None, 1, None, None, None, None, 1, None, None, None, None, None]
})打印(Df):
ECG_peaks Las_peaks
0 NaN NaN
1 NaN NaN
2 NaN NaN
3 NaN NaN
4 NaN NaN
5 1.0 NaN
6 NaN NaN
7 NaN 1.0
8 NaN NaN
9 1.0 NaN
10 NaN NaN
11 NaN NaN
12 NaN 1.0
13 NaN NaN
14 1.0 NaN
15 NaN NaN
16 NaN NaN
17 NaN NaN现在获取值为1的Las_peaks索引,如:
las_peaks = df.loc[df.Las_peaks==1].index对于ecg_peaks也是如此:
ecg_peaks = df.loc[df.ECG_peaks==1].index现在,我使用np.searchsorted得到最近的指数,其中每个激光峰值指数可以插入到心电图的峰值指数。
searches = [np.searchsorted(ecg_peaks, idx) for idx in las_peaks]那么,心电图指标中最近一次和最近一次之后的结果如下:
[(ecg_peaks[max(s-1, 0)], ecg_peaks[s]) for s in searches]对于此示例输入,输出如下:
[(5, 9), (9, 14)]其中5是激光峰在7处最近的前指数,9是7处激光峰的最近后指数。
同样,第12次激光指数为9,14。
Stack Overflow用户
发布于 2022-08-22 00:04:36
下面是一个使用pd.IntervalIndex()和get_indexer()的选项
ecg = df['ECG_peaks'].dropna().index
las = df['Las_peaks'].dropna().index
idx = pd.IntervalIndex.from_tuples(([(ecg[i],ecg[i+1]) for i in range(len(ecg)-1)]))
list(idx[idx.get_indexer(las)].to_tuples())页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73433777
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号