
使用开始日期和结束日期的两个变量绘制时间上的数据
我有一个大约有2000行的数据集。每一排都是重症监护室入院时的一次医院聚会。这是五年来收集的数据。
感兴趣的变量有:相遇次数、诊断类别、入院日期、出院日期。
我想要做的是,在这5年里,试着画出ICU每天的入住率。示例:
相遇号码: 786786诊断类别:结核病入院日期: 2022-01-20出院日期: 2022-01-30
因此,这个病人从01.20到01.30在ICU呆了10天。
另一次诊断相遇号: 786786诊断类别:癌症入院日期: 2022-01-21出院日期: 2022-01-28
最终目标是根据诊断类别,从最早的入院日和最近的出院日(x轴)开始,绘制每个日期的ICU占用率。对于x轴上的每一个5年的时间周期,将有一个诊断类别的酒吧。
我该怎么做呢?
谢谢(:
回答 1
Stack Overflow用户
发布于 2022-08-19 19:57:37
我自己也曾多次遇到这个问题。计算入住率的算法基本上是创建一个你想要绘制的天数的向量,然后为每一天,计算当天之前有多少人被接纳,并在那天之后出院。
我们需要一些真实的数据。假设你在5年内有2000名住院患者,而ICU的平均住院时间通常为3.5天,且具有伽玛或对数正态分布,我们可以创建一些合理的模拟数据,如下所示:
# Make data reproducible
set.seed(1)
df <- data.frame(Admit_date = sample(seq(as.POSIXct("2015-01-01"),
as.POSIXct("2020-01-01"), "day"),
2000, TRUE),
Diagnosis_category = sample(c("Respiratory",
"Infective",
"Post-op",
"Trauma"), 2000, TRUE),
Encounter_number = 56789123 + 1:2000)
df$Discharge_date <- df$Admit_date + 86400 * rgamma(2000, sh = 2, scale = 1.75)
df$Discharge_date <- as.Date(df$Discharge_date)
df$Admit_date <- as.Date(df$Admit_date)
df <- df[order(df$Admit_date), c(3, 1, 4, 2)]
rownames(df) <- NULL
head(df)
#> Encounter_number Admit_date Discharge_date Diagnosis_category
#> 1 56790418 2015-01-01 2015-01-02 Post-op
#> 2 56789614 2015-01-05 2015-01-10 Post-op
#> 3 56790100 2015-01-05 2015-01-12 Post-op
#> 4 56790644 2015-01-07 2015-01-07 Trauma
#> 5 56789943 2015-01-08 2015-01-09 Respiratory
#> 6 56790066 2015-01-08 2015-01-13 Trauma假设这与您自己的数据相似,我们现在可以像这样计算每天的占用率:
library(tidyverse)
# Create vector of all dates you wish to plot
days <- seq(as.Date("2015-01-01"), as.Date("2020-01-01"), "day")
plot_df <- df %>%
group_by(Diagnosis_category) %>%
summarize(date = days, count = sapply(days, function(x) {
sum(Admit_date <= x & Discharge_date >= x)
}))现在我们准备好阴谋了。在我的示例中,我们只有4个诊断类别,试图在一个面板上绘制超过1600列已经是一项挑战。如果你试图把你所有的诊断类别都放在一个单独的面板上,你就会被弄得一团糟。更糟糕的是,在每个诊断类别中只有少数患者( Covid高峰期间除外),因此图中只会有几个离散的步骤。我认为最好在这种情况下使用方面:
ggplot(plot_df, aes(date, count, fill = Diagnosis_category,
color = Diagnosis_category)) +
geom_col() +
facet_wrap(.~Diagnosis_category) +
theme_minimal(base_size = 16) +
theme(legend.position = "none")
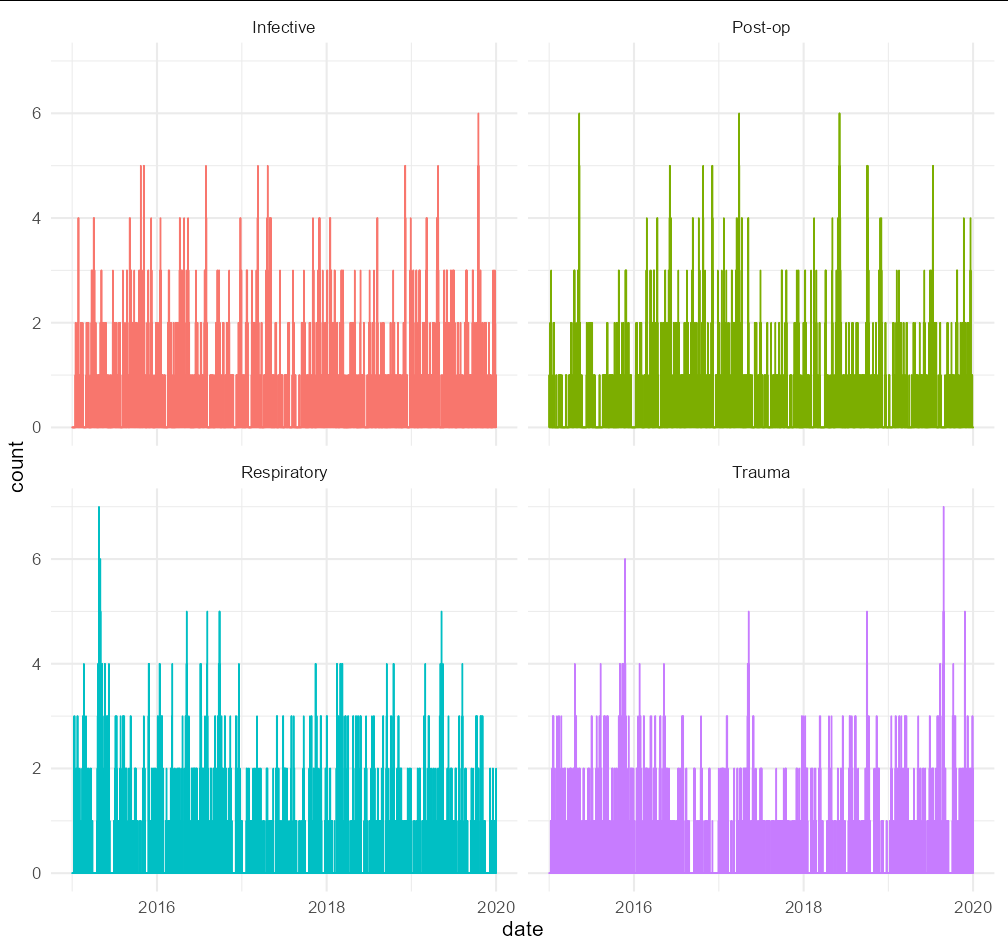
除非有一个特定的点,您希望您的数据与这类地块(如在科维德高潮期间的巨大占用率),你可能想要一个不同的总结衡量。您可以尝试按诊断类别和月份对plot_df进行分组,然后计算每月平均占用率。
https://stackoverflow.com/questions/73420900
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号