
如何在数据仓库中对产品进行分组?
如何在数据仓库中对产品进行分组?
提问于 2022-08-18 16:19:29
目前的数据:
PROD Party x y Currency Parent Product agg_x agg_y
iphone 13 pro 5AAZ27778 60 9.927 USD Apple Cash 120 19.854
iphone 13 6AAL321054 30 20.24441848 USD Apple Cash 30 20.24441848
iphone 12 9G351866 70 3.747318956 USD Apple Cash 140 7.494637912
iphone 12 9G351866 70 3.747318956 USD Apple Cash 140 7.494637912
iphone se 3G140868 750 122.6481749 USD Apple Cash 750 122.6481749
iphone 13 pro 5AAZ27778 60 9.927 USD Apple Cash 120 19.854预期数据:
Product Party x y Currency Parent
Cash 5AAZ27778 120 19.854 USD Apple
iphone 13 pro 5AAZ27778 60 9.927 USD Apple
iphone 13 pro 5AAZ27778 60 9.927 USD Apple
Cash 6AAL321054 30 20.24441848 USD Apple
iphone 13 6AAL321054 30 20.24441848 USD Apple
Cash 9G351866 140 7.494637912 USD Apple
iphone 12 9G351866 70 3.747318956 USD Apple
iphone 12 9G351866 70 3.747318956 USD Apple
Cash 3G140868 750 122.6481749 USD Apple
iphone se 3G140868 750 122.6481749 USD Apple

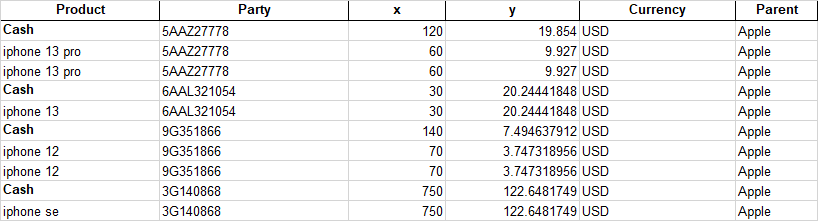
我想要将当前的dataframe修改为预期的数据。在预期的数据框架中,“当事方”栏中的共同记录应放在“现金”下,即总金额下。在当前的dataframe中,agg_x和agg_y列是基于列x和y的列"party“的结果。请提供代码将当前数据转换为预期的数据。感谢你在这方面的帮助!
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-08-18 16:42:04
考虑到没有干净的标头,最好的方法是拆分和concat,用现金删除副本,然后重新排序:
cols1 = ['PROD', 'Party', 'x', 'y', 'Currency', 'Parent']
cols2 = ['Product', 'Party', 'agg_x', 'agg_y', 'Currency', 'Parent']
out = (pd.concat([df[cols2].set_axis(cols1, axis=1)
.drop_duplicates('Party'),
df[cols1]])
.sort_values(by='Party')
)产出:
PROD Party x y Currency Parent
4 Cash 3G140868 750 122.648175 USD Apple
4 iphone se 3G140868 750 122.648175 USD Apple
0 Cash 5AAZ27778 120 19.854000 USD Apple
0 iphone 13 pro 5AAZ27778 60 9.927000 USD Apple
5 iphone 13 pro 5AAZ27778 60 9.927000 USD Apple
1 Cash 6AAL321054 30 20.244418 USD Apple
1 iphone 13 6AAL321054 30 20.244418 USD Apple
2 Cash 9G351866 140 7.494638 USD Apple
2 iphone 12 9G351866 70 3.747319 USD Apple
3 iphone 12 9G351866 70 3.747319 USD Apple页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73406447
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号