
如何解决运行sklearn2PMML时内存不足的问题
我试图将我用python编写的SVM分类器模型打包为PMML,以便在Flink项目中使用它。
参考资料:https://github.com/aedenj/flink-machine-learning-fish-market-example/blob/main/model/model.ipynb
该模型运行良好,并返回预期结果,如下所示(不确定重复输出,但这不是问题所在)。
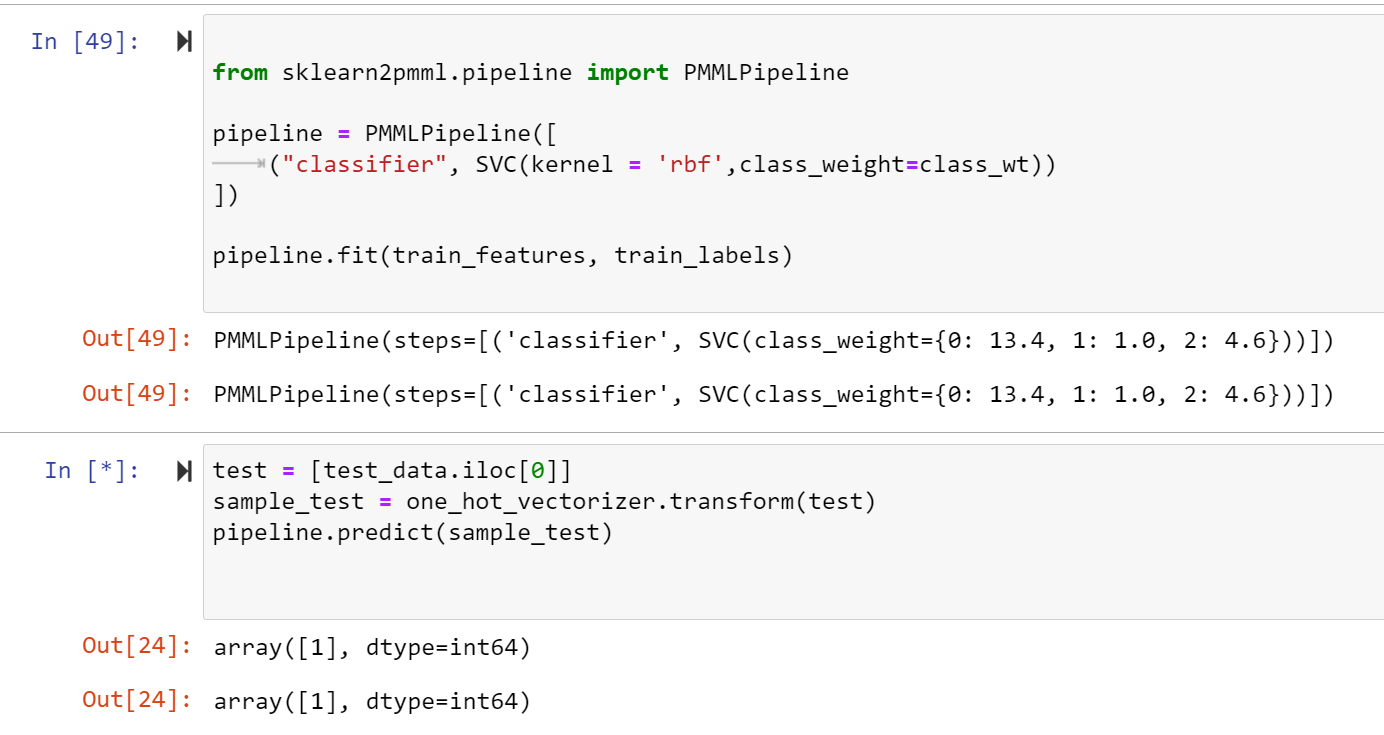
当我试图将它打包为一个PMML文件时,我会得到“请求的数组大小超过VM限制”错误。
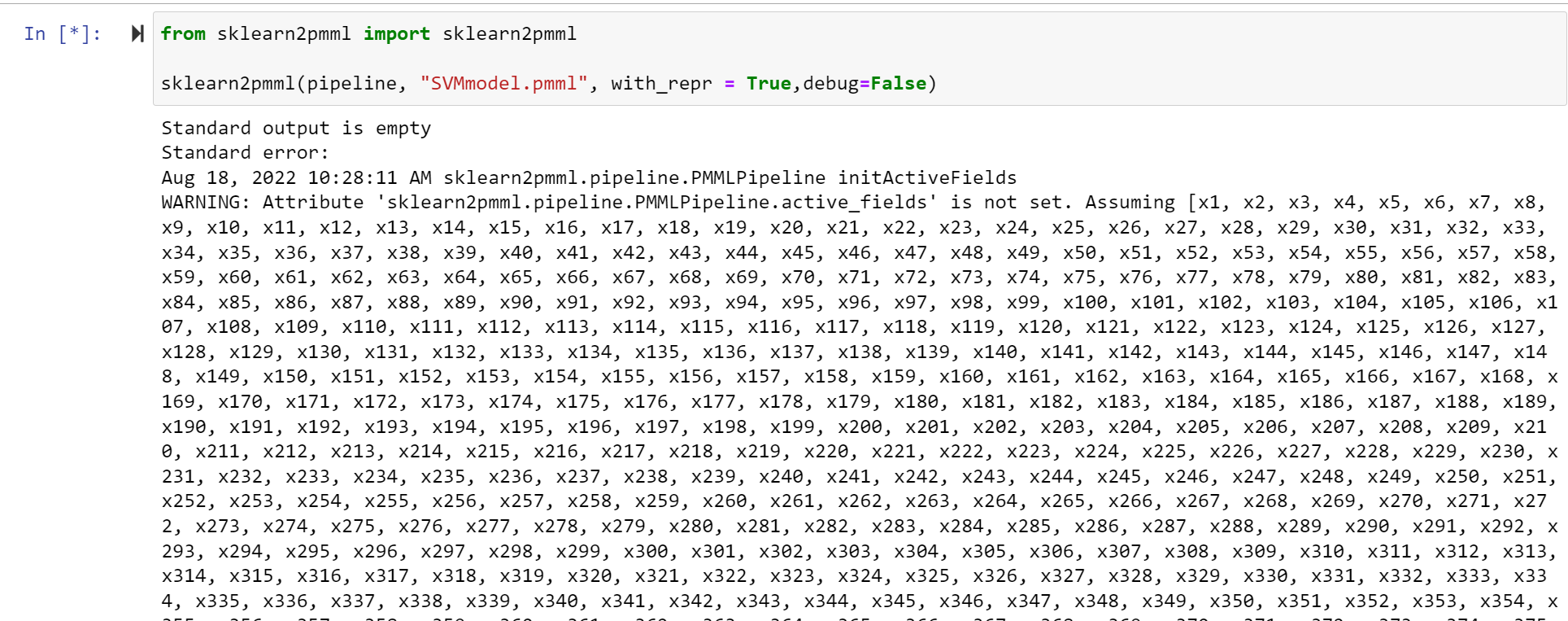
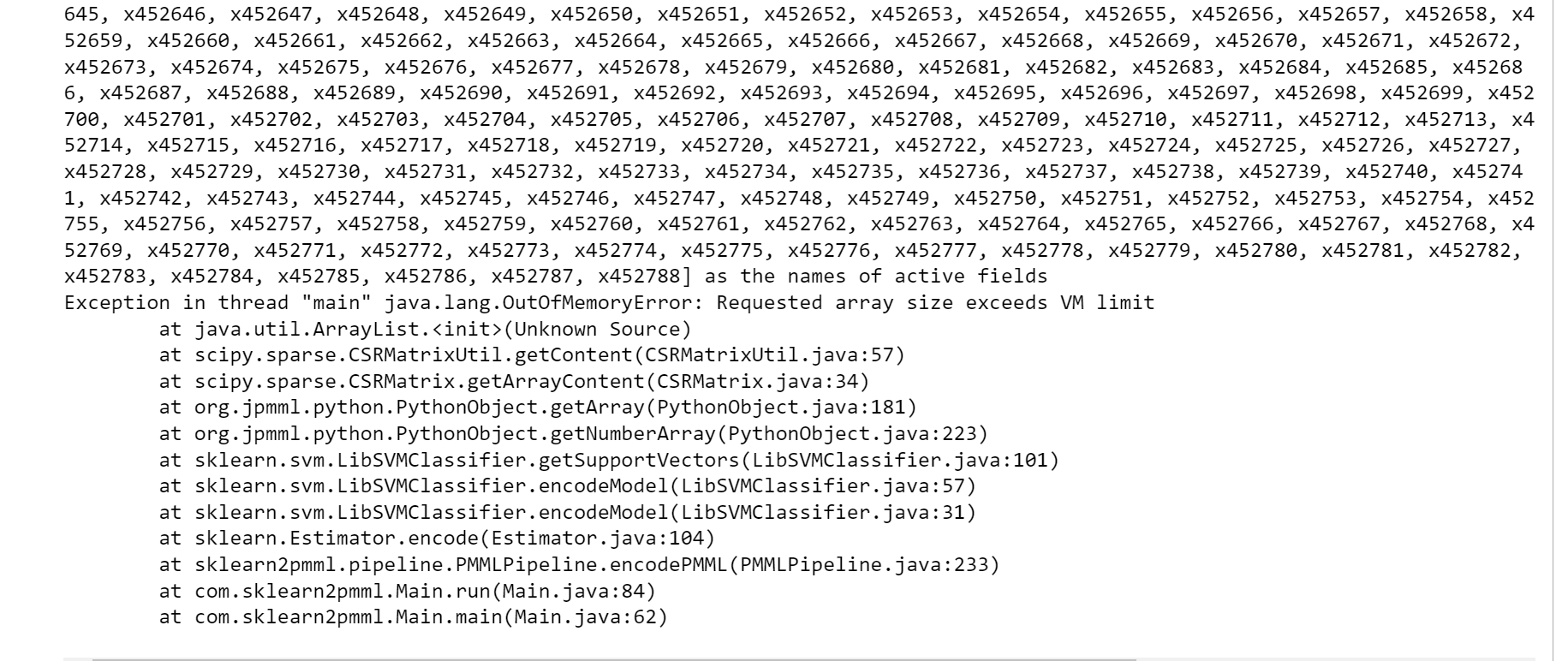
有人能告诉我这里发生了什么吗?
我想知道这是否与未设置的活动字段有关。训练数据是一种单热点编码矢量表示.
回答 1
Stack Overflow用户
发布于 2022-09-11 19:18:15
sklearn2pmml.sklearn2pmml实用程序函数通过Python的subprocess.Popen调用Java可执行文件。如果默认的内存太“小”,则可以通过指定-Xms和/或-Xmx Java可执行选项来增加其大小。
有两种方法可以做到这一点:
variable.
- Starting从 0.86.2导出所需的
JAVA_OPTS环境配置,sklearn2pmml.sklearn2pmml实用程序函数支持java_home和java_opts参数.
样本使用情况:
pipeline = PMMLPipeline(..)
sklearn2pmml(pipeline, "pipeline.pmml", java_opts = ["-Xms2G", "-Xmx8G"])无论如何,在目前的情况下,请把这个OutOfMemoryError作为一个警告标志,您的装配模型对象有问题。在模型之外执行OHE,然后将0.5M输入的特征值输入到(PMML-)模型中是没有意义的。
https://stackoverflow.com/questions/73401502
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号