
是否有一个函数可以在不使用Python删除整行的情况下删除行中的重复项?
是否有一个函数可以在不使用Python删除整行的情况下删除行中的重复项?
提问于 2022-08-12 14:46:05
import pandas as pd
data=[["John","Alzheimer's","Infection","Alzheimer's"],["Kevin","Pneumonia","Pneumonia","Tuberculosis"]]
df=pd.DataFrame(data,columns=['Name','Problem1','Problem2','Problem3'])

在这个数据框架中,我希望阅读每一行并删除重复项,以便每个人的问题只报告一次。这意味着在第1行中删除“老年痴呆症”作为复制。我尝试了drop_duplicates()函数,但这删除了整个行。
任何帮助都将不胜感激!
回答 4
Stack Overflow用户
发布于 2022-08-12 15:04:02
首先,重新创建一个数据示例:
import pandas as pd
data=[["John","Alzheimer's","Infection","Alzheimer's"],["Kevin","Pneumonia","Pneumonia","Tuberculosis"]]
df=pd.DataFrame(data,columns=['Name','Problem1','Problem2','Problem3'])
df
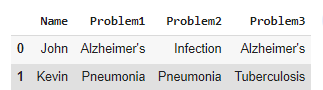
现在要用空空间删除或替换重复:
df['Problem2']=df.apply(lambda x:x["Problem2"] if not(x["Problem2"]==x['Problem1']) else " ",axis=1)
df['Problem3']=df.apply(lambda x:x["Problem3"] if not(x["Problem3"]==x['Problem2'] or x["Problem3"]==x['Problem1']) else " ",axis=1)
df
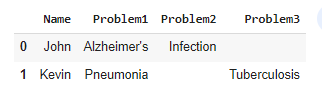
Stack Overflow用户
发布于 2022-08-12 15:05:02
为此,您可以尝试使用df.duplicated-function。这类似于df.drop_duplicates,但返回一个布尔序列,而不是删除重复项。然后,可以通过此布尔序列将值设置为None来索引初始数据。
Stack Overflow用户
发布于 2022-08-12 22:30:50
使用apply和duplicated。
确保使用axis=1参数在apply上应用于行而不是列。duplicated将返回一个布尔序列,默认情况下,该序列将第一个匹配项设置为“False”。在~中使用与本系列相反的值将保留我们的非复制值,而忽略重复的值。
示例设置
import pandas as pd
data=[["John","Alzheimer's","Infection","Alzheimer's"],["Kevin","Pneumonia","Pneumonia","Tuberculosis"]]
df=pd.DataFrame(data,columns=['Name','Problem1','Problem2','Problem3'])
df
Name Problem1 Problem2 Problem3
0 John Alzheimer's Infection Alzheimer's
1 Kevin Pneumonia Pneumonia Tuberculosis去叠
deduped_df = df.apply(lambda row: row[~row.duplicated()],axis=1)输出
>>> deduped_df
Name Problem1 Problem2 Problem3
0 John Alzheimer's Infection NaN
1 Kevin Pneumonia NaN Tuberculosis页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73335908
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号