
在r中的摘要函数中进行过滤或基于filter - Reprex对前面的行进行求和。
我试图根据name_ex的筛选器和指定的循环数来对前面的数据行进行求和。更具体而言:
目标:分别对前3行stat1和stat2进行求和。只有在符合name_ex标准的情况下,这些总和才会出现。ie只与stat1和stat2从史蒂夫的行(之和史蒂夫的数据,比尔的数据,但避免使用史蒂夫的数据在比尔的。)
附加目标:最好是,而不是仅对最后3行进行求和,我想根据一个循环筛选器对stat1和stat2行进行求和。我不确定这在dplyr函数中是否可以实现,或者我是否需要编写一个函数来实现它。
Work: --我使用group_by函数以它想要的形式获取数据,这样我就可以使用动物园对最后3行数据进行求和。
问题:函数只调用最后3行数据,而不考虑标准。这是个问题,因为我无法按每个人的名字将数据分开(比尔从史蒂夫的名字中提取)。此外,我正在寻找一个简单的筛选器,它可以拉出符合name_ex标准并且轮数在10到12之间(累计)的行。
#Load packages
library(dplyr)
library(tidyverse)
library(zoo)
#Reprex
name_ex <- c("steve", "steve","steve", "steve","steve","steve", "steve", "bill", "bill", "bill", "bill", "bill", "bill", "bill", "bill", "john","john","john", "john","john","john", "john")
rounds <- c(4, 4, 4, 2, 4, 4, 4, 4, 4, 4, 2, 4, 2, 4, 2, 4, 4, 4, 4, 4, 4, 2)
t_id <- c(1, 2, 3, 4, 1, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 4, 1, 2, 3, 4)
year <- c(2019, 2019,2019, 2019, 2020, 2020, 2020, 2019, 2019, 2019, 2019, 2020, 2020, 2020, 2020, 2019, 2019, 2019, 2020, 2020, 2020, 2020)
stat1 <- c(3.2, 3.4, -1.4, 2.1, 1.3, -1.7, -1.7, 1.1, 2.0, 1.3, .7, 1.5, 1.2, 2.5, 3.6, -1.1, 0.4, -1.2, -1.1, 1.6, 1.3, -2.7)
stat2 <- c(1.7, 1.2, 1.3, -.4, 1.1, 2.1, -2.1, .6, 1.1, 3.4, -1.1, -1.7, -1.3, 1.1, 2.4, 1.3, 2.6, .6, 1.3, .7, 2.3, -2.4)
event_n <- c(1, 2, 3, 4, 5, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 4, 5, 6, 7, 8)
test_df <- do.call(rbind, Map(data.frame, name_ex =name_ex, year = year, t_id = t_id, event_n = event_n, rounds =rounds, stat1 = stat1, stat2 = stat2))
#Sum the previous 3 columns of data for stat1 and stat2
test_df2 <- test_df %>%
group_by(name_ex, t_id, year)
test_df2$stat1_sum <- lag(rollsumr(test_df2$stat1, k = 3, fill = NA))
test_df2$stat2_sum <- lag(rollsumr(test_df2$stat2, k = 3, fill = NA))
test_df2
#bad attempt at filtering for name
#test_df2$stat1_sum <- lag(rollsumr(test_df2$stat1[name_ex == name_ex], k = 3, fill = NA))回答 1
Stack Overflow用户
发布于 2022-08-11 16:09:28
我认为,如果您首先将数据转换为长格式,那么您的第一个问题可以很容易地使用dplyr回答。(这也使您的数据整洁。)
longDF <- test_df %>%
pivot_longer(
starts_with("stat"),
names_to="Statistic",
values_to="Value"
) %>%
arrange(Statistic, name_ex, year) %>%
group_by(name_ex, Statistic) %>%
mutate(
ValueLag1=lag(Value),
ValueLag2=lag(Value, 2)
)
longDF
# A tibble: 44 × 9
# Groups: name_ex, Statistic [6]
name_ex year t_id event_n rounds Statistic Value ValueLag1 ValueLag2
<chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> <dbl>
1 bill 2019 1 1 4 stat1 1.1 NA NA
2 bill 2019 2 2 4 stat1 2 1.1 NA
3 bill 2019 3 3 4 stat1 1.3 2 1.1
4 bill 2019 4 4 2 stat1 0.7 1.3 2
5 bill 2020 1 5 4 stat1 1.5 0.7 1.3
6 bill 2020 2 6 2 stat1 1.2 1.5 0.7
7 bill 2020 3 7 4 stat1 2.5 1.2 1.5
8 bill 2020 4 8 2 stat1 3.6 2.5 1.2
9 john 2019 1 1 4 stat1 -1.1 NA NA
10 john 2019 2 2 4 stat1 0.4 -1.1 NA
# … with 34 more rows使用group_by()可以防止一个人的数据传递给另一个人。您可以在上面的输出中清楚地看到效果。
现在计算“最后三项之和”也很简单:
longDF %>%
mutate(SumOfLastThree=Value + ValueLag1 + ValueLag2) %>%
select(-ValueLag1, -ValueLag2)
# A tibble: 44 × 8
# Groups: name_ex, Statistic [6]
name_ex year t_id event_n rounds Statistic Value SumOfLastThree
<chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
1 bill 2019 1 1 4 stat1 1.1 NA
2 bill 2019 2 2 4 stat1 2 NA
3 bill 2019 3 3 4 stat1 1.3 4.4
4 bill 2019 4 4 2 stat1 0.7 4
5 bill 2020 1 5 4 stat1 1.5 3.5
6 bill 2020 2 6 2 stat1 1.2 3.4
7 bill 2020 3 7 4 stat1 2.5 5.2
8 bill 2020 4 8 2 stat1 3.6 7.3
9 john 2019 1 1 4 stat1 -1.1 NA
10 john 2019 2 2 4 stat1 0.4 NA
# … with 34 more rows这能给你预期的产出吗?
考虑一下
longDF %>%
mutate(
CumulativeRounds=ifelse(
row_number() == 1,
rounds,
rounds+lag(rounds)
)
)
# A tibble: 44 × 10
# Groups: name_ex, Statistic [6]
name_ex year t_id event_n rounds Statistic Value ValueLag1 ValueLag2 CumulativeRounds
<chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
1 bill 2019 1 1 4 stat1 1.1 NA NA 4
2 bill 2019 2 2 4 stat1 2 1.1 NA 8
3 bill 2019 3 3 4 stat1 1.3 2 1.1 8
4 bill 2019 4 4 2 stat1 0.7 1.3 2 6
5 bill 2020 1 5 4 stat1 1.5 0.7 1.3 6
6 bill 2020 2 6 2 stat1 1.2 1.5 0.7 6
7 bill 2020 3 7 4 stat1 2.5 1.2 1.5 6
8 bill 2020 4 8 2 stat1 3.6 2.5 1.2 6
9 john 2019 1 1 4 stat1 -1.1 NA NA 4
10 john 2019 2 2 4 stat1 0.4 -1.1 NA 8
# … with 34 more rows所以
longDF %>%
select(-ValueLag1, -ValueLag2) %>%
mutate(
CumulativeRounds=ifelse(
row_number() == 1,
rounds,
rounds+lag(rounds)
)
) %>%
filter(CumulativeRounds >= 8 & CumulativeRounds <= 10)
# A tibble: 22 × 8
# Groups: name_ex, Statistic [6]
name_ex year t_id event_n rounds Statistic Value CumulativeRounds
<chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
1 bill 2019 2 2 4 stat1 2 8
2 bill 2019 3 3 4 stat1 1.3 8
3 john 2019 2 2 4 stat1 0.4 8
4 john 2019 4 4 4 stat1 -1.2 8
5 john 2020 1 5 4 stat1 -1.1 8
6 john 2020 2 6 4 stat1 1.6 8
7 john 2020 3 7 4 stat1 1.3 8
8 steve 2019 2 2 4 stat1 3.4 8
9 steve 2019 3 3 4 stat1 -1.4 8
10 steve 2020 3 7 4 stat1 -1.7 8我相信这是你想要的。
编辑
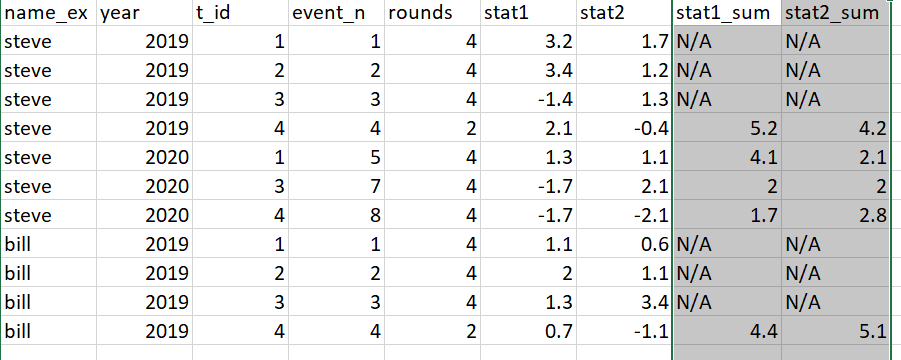
OP现在发布了一张图片,澄清了“最后三行”的含义。我为他们问题的第一部分建议的解决方案可以很容易地适应,以产生所需的结果。
test_df %>%
pivot_longer(
starts_with("stat"),
names_to="Statistic",
values_to="Value"
) %>%
arrange(Statistic, name_ex, year, t_id) %>%
group_by(name_ex, Statistic) %>%
mutate(
ValueLag1=lag(Value),
ValueLag2=lag(Value, 2),
ValueLag3=lag(Value, 3),
SumOfPreviousThree=ValueLag1 + ValueLag2 + ValueLag3
) %>%
select(-ValueLag1, -ValueLag2, -ValueLag3)
# A tibble: 44 × 8
# Groups: name_ex, Statistic [6]
name_ex year t_id event_n rounds Statistic Value SumOfPreviousThree
<chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
1 bill 2019 1 1 4 stat1 1.1 NA
2 bill 2019 2 2 4 stat1 2 NA
3 bill 2019 3 3 4 stat1 1.3 NA
4 bill 2019 4 4 2 stat1 0.7 4.4
5 bill 2020 1 5 4 stat1 1.5 4
6 bill 2020 2 6 2 stat1 1.2 3.5
7 bill 2020 3 7 4 stat1 2.5 3.4
8 bill 2020 4 8 2 stat1 3.6 5.2
9 john 2019 1 1 4 stat1 -1.1 NA
10 john 2019 2 2 4 stat1 0.4 NA
# … with 34 more rows若要返回OP的无序格式,请将以下内容添加到管道的末尾:
%>%
pivot_wider(
values_from=c(Value, SumOfPreviousThree),
names_from=Statistic
)https://stackoverflow.com/questions/73323518
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号