
增加具有数据增强的类的实例
增加具有数据增强的类的实例
提问于 2022-08-10 12:26:00
我正在使用一些类的查尔德斯数据集https://prior.allenai.org/projects/charades来检测室内动作。
我的数据集的结构如下:
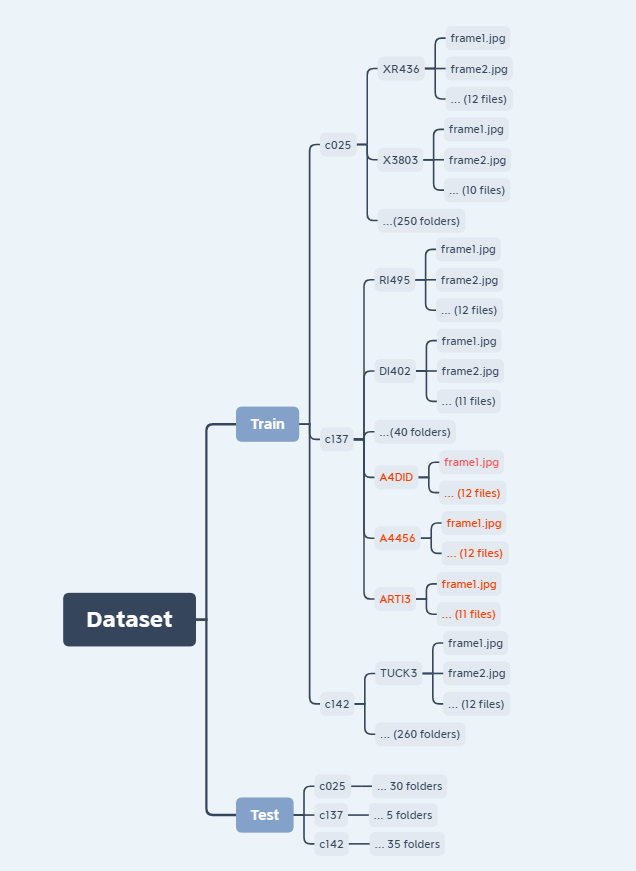
其中:
- c025、c137和c142是行动;
- XR436有分割视频的帧结果,其中用户正在执行动作c025,而对于X3803,.总共有250个文件夹。
- RI495有分割视频的帧结果,其中用户正在执行动作c137,而对于DI402,.总共有40个文件夹。
- TUCK3有分割视频的帧结果,其中用户正在执行c142动作,其余的则是相同的。总共有260个文件夹。
如您所见,类c137的实例相对于类c025和c142来说是相当不平衡的。因此,我想使用数据增强来增加这个类的实例数。这个想法是创建具有特定转换的双文件夹。例如,将A4DID文件夹创建为RI495的孪生文件,对每个框架进行均衡,将A4456文件夹创建为GrayScale中的RI495的孪生文件,将ARTI3创建为DI402的孪生文件,并对框架进行旋转,等等。每个文件夹的转换模式都可以是相同的。只是对增加实例的数量感兴趣。
你知道怎么继续吗?我正在使用Pytorch,我尝试了使用torchvision.transforms和torch.utils.data的DataLoader,但是我还没有达到我想要的结果。知道该怎么做吗?
PS:过采样的c025和c142不是一个选择,因为分类器不能很好地学习如此有限的数量的例子。
提前谢谢你
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-08-10 14:17:19
几点想法:
- 标准的实践是动态地使用转换;也就是说,每次加载数据示例时,都会使用随机参数设置应用一组组合或顺序的转换操作。因此,每次加载数据时,产生的
x(输入)都是不同的。这可以通过定义一个转换堆栈来实现,这些转换将应用于每个数据示例,因为它被加载到一个py呼机dataset对象(见这里)中。这有助于提供数据增强。 - 类不平衡是一个有点不同的问题,通常由一个.)过采样(如果使用上述转换解决方案,这是可以接受的,因为过采样的示例将有不同的转换应用)或b。在损失计算中,这些例子的权重过大.当然,这两种方法都不能解释接收到分发外测试示例的风险,这种风险越高,对于给定类的示例就越少、越少。前者可以通过定义一个自定义
Sampler对象来实现,该对象以类平衡的方式从您的数据集中生成示例。后者可以通过将权重传递给损失函数来实现(许多传递丢失函数,如CrossEntropyLoss已经支持权重)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73306305
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号