
如何区分解析器和词法规则?
有时,我在词法规则和解析规则之间有点混淆,而且这里上有一个很好的线程。例如,在以下方面:
value
: string CAST_OPERATOR type
;
string
: S_QUOTE STRING_VALUE S_QUOTE
;
# <-- what is this?
type
: 'date' | 'string'
;
STRING_VALUE
: [a-zA-Z0-9-]+
;
CAST_OPERATOR
: '::'
;对于type --这要么是字符串(或字符流) date,要么是string。这是一个词法规则还是一个解析规则?我想我可以把它更多地分解成:
type
: DATE_TYPE | STRING_TYPE
;
DATE_TYPE
: 'date'
;
STRING_TYPE
: 'string'
;但我仍然不太确定上述哪一个更可取,以及为什么会如此。前两条规则-- value和string --在我看来很清楚是解析规则--最后两条规则--在我看来-- STRING_VALUE和CAST_OPERATOR --在我看来是明确的词法规则(不过,凭直觉,我无法给出正确的解释)。那么,为什么type会是这样还是那样呢?
实际上,我发现的唯一实际区别是,一个词法规则可以包含一个字符类,而一个解析规则不能。
Update:我想另一件事是,词法规则是终端,它不会提供任何部件的细分。例如,在下面我们可以将$55分解为$和55
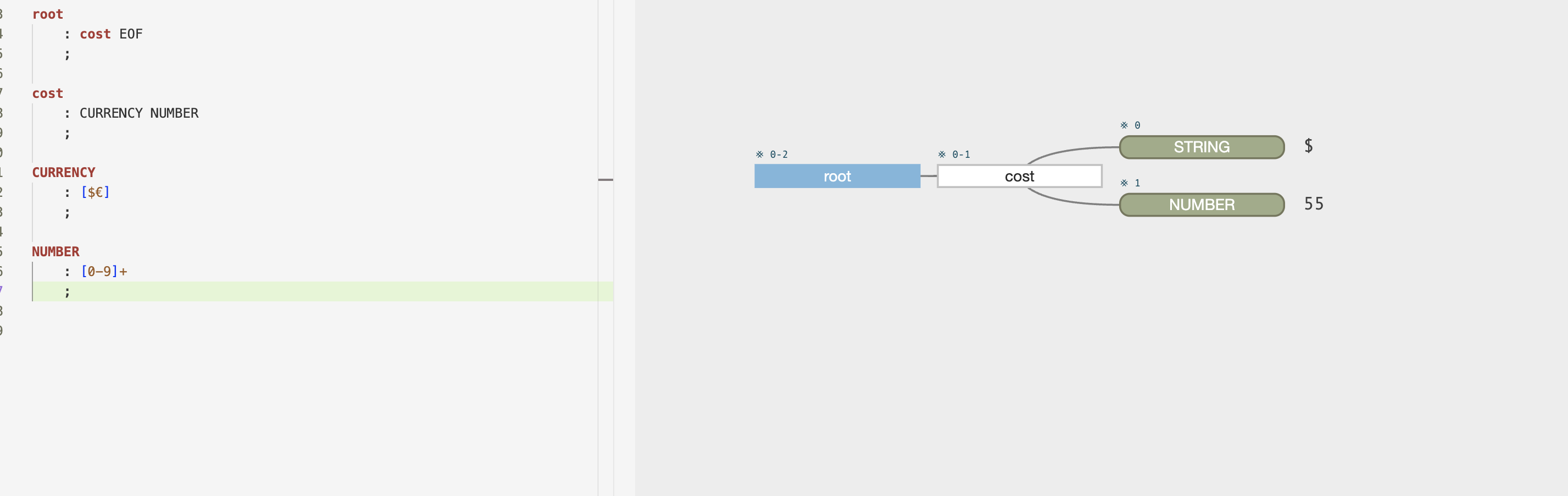
但是,如果我们将cost设置为一个词法规则,它将不会进一步分解它:
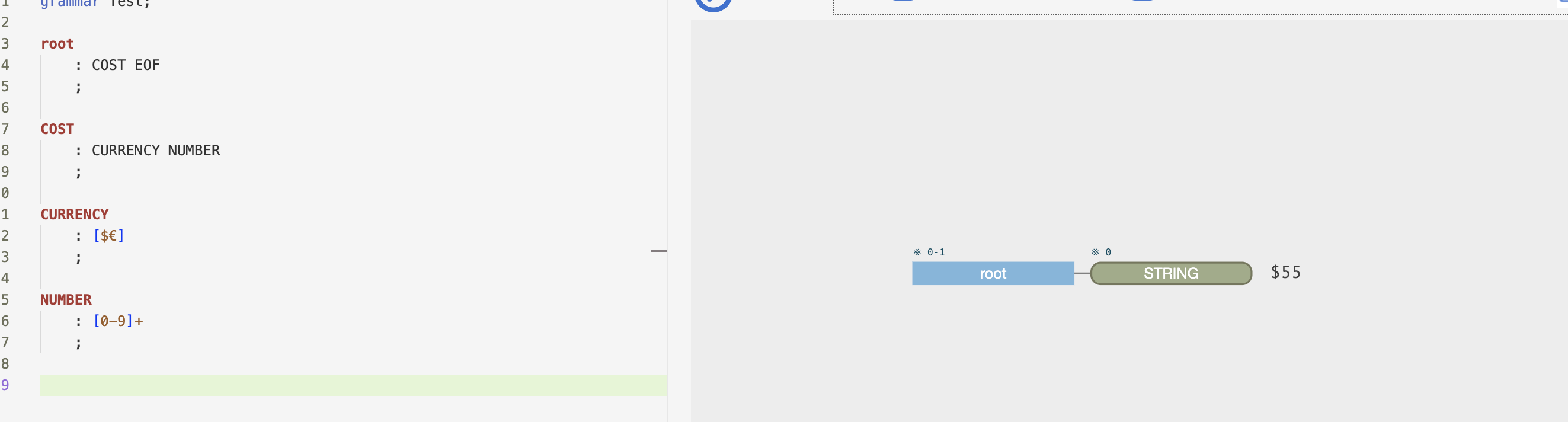
因此,从根本上说,词汇规则是原子和终端,而解析规则更像是一个分子,它由可以在其中看到的各个部分(原子)组成。这是一种很好的描述/理解吗?
回答 1
Stack Overflow用户
发布于 2022-08-09 22:38:52
你的“更新”在正确的轨道上。这是一个明确的区别。
您还需要了解ANTLR管道。也就是说,字符流由Lexer规则处理,以生成标记流(类推中为原子)。它不使用递归下降规则匹配,而是尝试将您的输入与所有Lexer规则匹配。其中:
- 匹配最长输入字符序列的规则将“获胜”。
- 如果多个Lexer规则匹配相同的长度字符序列,那么首先发生的规则将“获胜”。
一旦您获得了“原子”流(也称为Tokens),那么ANTLR就会使用解析器规则(从开始规则中递归地)来匹配令牌序列。
https://stackoverflow.com/questions/73298120
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号