
LinearRegression TypeError
LinearRegression TypeError
提问于 2022-08-06 23:40:09
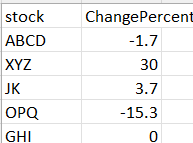
上面的屏幕截图引用为as: sample.xlsx。我在使用LinearRegression()函数获取每个股票的beta版时遇到了困难。输入:
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
df = pd.read_excel('sample.xlsx')
mean = df['ChangePercent'].mean()
for index, row in df.iterrows():
symbol = row['stock']
perc = row['ChangePercent']
x = np.array(perc).reshape((-1, 1))
y = np.array(mean)
model = LinearRegression().fit(x, y)
print(model.coef_)输出:第16行: model = LinearRegression().fit(x,y) "Singleton数组%r不能被视为有效集合“%x TypeError: Singleton数组(3.34)不能被视为有效集合。如何使集合有效,以便为每个股票获得一个beta值(model.coef_)?
回答 1
Stack Overflow用户
发布于 2022-08-07 00:50:20
X和y必须具有相同的形状,所以您需要将x和y都整形为1行和1列。在这种情况下,恢复如下:
np.array(mean).reshape(-1,1)或np.array(mean).reshape(1,1)
假设您正在训练5个分类器,每个分类器只有一个值,这5个模型将“了解”线性回归系数为0,截距为3.37 (y),这并不奇怪。
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
df = pd.DataFrame({
"stock": ["ABCD", "XYZ", "JK", "OPQ", "GHI"],
"ChangePercent": [-1.7, 30, 3.7, -15.3, 0]
})
mean = df['ChangePercent'].mean()
for index, row in df.iterrows():
symbol = row['stock']
perc = row['ChangePercent']
x = np.array(perc).reshape(-1,1)
y = np.array(mean).reshape(-1,1)
model = LinearRegression().fit(x, y)
print(f"{model.intercept_} + {model.coef_}*{x} = {y}")从算法的角度来看,这是正确的,但这没有任何实际意义,因为你只是提供一个例子来训练每个模型。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73263951
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号