
如何根据特定的标准只获得某些行的数据?
如何根据特定的标准只获得某些行的数据?
提问于 2022-08-05 22:49:34
数据中有数千行数据,如下所示:
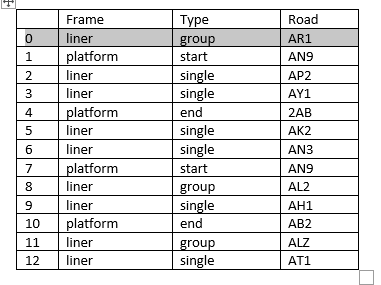
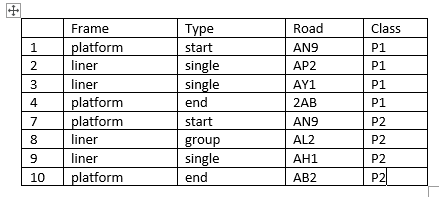
我希望能够只提取平台(“框架”列)的每个起点(“类型”列)到平台(“框架”列)的每一端(“框架”列)中存在的所有数据行作为下面的输出,并将类列中的数据命名为P1 (第一个平台开始和平台结束中的所有行)、P2 (第二个平台开始和结束)、P3、P4等:
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-08-06 00:27:14
欢迎来到堆栈溢出!
我会这么做的。这可能不是最干净的解决方案,但我认为它能做你想做的事情。
# Set up reproductible example (reprex)
import pandas as pd
df = pd.DataFrame({
"Frame": ["liner", "platform", "liner", "liner", "platform",
"liner", "platform", "liner", "platform", "liner"],
"Type": ["group", "start", "single", "single", "end",
"single", "start", "group", "end", "single"]
})
# Frame Type
# 0 liner group
# 1 plateform start
# 2 liner single
# 3 liner single
# 4 plateform end
# 5 liner single
# 6 plateform start
# 7 liner group
# 8 plateform end
# 9 liner single步骤1:从平台开始到结束选择行
start_indices = df.index[(df.Frame == "platform") & (df.Type == "start")]
end_indices = df.index[(df.Frame == "platform") & (df.Type == "end")]
df = pd.concat([
df[start:end+1] for start, end in zip(start_indices, end_indices)
])步骤2:添加带有平台号的列
df["Class"] = (
pd.Series(
[f"P{n}" for n in range(1, len(start_indices) + 1)],
index=start_indices
)
.reindex(df.index)
.fillna(method="ffill")
)你得到的是:
df
# Frame Type Class
# 1 platform start P1
# 2 liner single P1
# 3 liner single P1
# 4 platform end P1
# 6 platform start P2
# 7 liner group P2
# 8 platform end P2页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73255923
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号