
将矩阵中的余弦相似嵌入转换为熊猫数据
将矩阵中的余弦相似嵌入转换为熊猫数据
提问于 2022-08-03 16:19:12
我在将数组中的余弦相似性分配给熊猫Dataframe时遇到了问题。我使用下面的代码测试了余弦相似矩阵
# Find the closest 5 sentences of the corpus for each query sentence based on cosine similarity
top_k = min(5, len(corpus))
for query in queries:
query_embedding = model.encode(query, convert_to_tensor=True)
# We use cosine-similarity and torch.topk to find the highest 5 scores
cos_scores = util.cos_sim(query_embedding, corpus_embeddings)[0]
top_results = torch.topk(cos_scores, k=top_k)
print("\n\n======================\n\n")
print("Query:", query)
print("\nTop 5 most similar sentences in corpus:")
for score, idx in zip(top_results[0], top_results[1]):
print(corpus[idx], "(Score: {:.4f})".format(score))下面是代码产生的输出
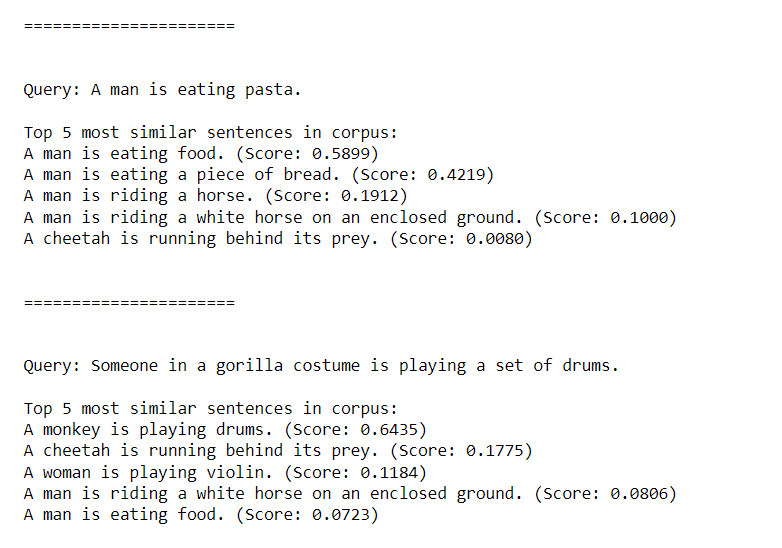
不过,我想将相似性评分写回结构如下的Dataframe
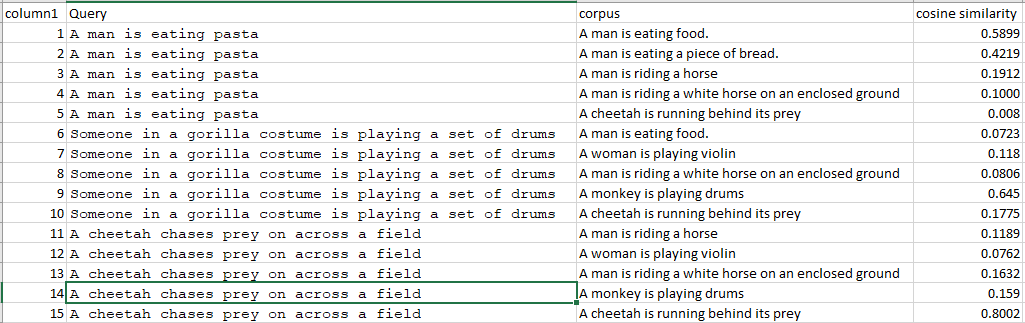
复制示例的虚拟数据代码
df1 = pd.DataFrame(columns=['Query','Corpus'])
df1['Query'] = ["A man is eating pasta","A man is eating pasta","A man is eating pasta","A man is eating pasta","A man is eating pasta"]
df1['Corpus'] = ["A man is eating food","A man is eating a piece of bread.","A man is riding a horse","A man is riding a white horse on an enclosed ground","A cheetah is running behind its prey"]
df1**详细示例可在此处找到https://www.codegrepper.com/code-examples/python/sentence+transformers **
我确实提到了类似的问题Cosine Similarity for Sentences in Dataframe & Cosine similarity of rows in pandas DataFrame,但是它们没有回答我的问题。任何指示都会有帮助。
回答 1
Stack Overflow用户
发布于 2022-08-03 16:42:20
我不知道你试过什么,但是一本简单的字典会是我想要的。
dc = {'Query':[],'Corpus':[],'Cos_sim':[]}
for query in queries:
query_embedding = model.encode(query, convert_to_tensor=True)
cos_scores = util.cos_sim(query_embedding, corpus_embeddings)[0]
top_results = torch.topk(cos_scores, k=top_k)
dc['Query'] = [query] * 5
for score, idx in zip(top_results[0], top_results[1]):
dc['Corpus'] = corpus[idx]
dc['Cos_sim'] = score在那之后就做吧
df = pd.DataFrame(dc)会给你通缉的df
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73224616
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号