
如何从数据集生成图形矩阵,其中每个变量都被指定为二进制、真/假-将数据转换为所需的格式?
提前感谢您的帮助
我正试图生成一个图形矩阵,以说明每一种农林业系统的科学论文数量,报告某一生物多样性指标。
上下文
使用描述性汇总统计数据,分析关于农林业系统、生物多样性和生态系统服务方面的大型森林农林业数据库,作为系统制图审查的一部分。
目标
说明为每个农林系统报告各种生物多样性指标的科学论文的数量。为此,我要生成一个图形矩阵(例如邻接矩阵、气球图),它显示了报告每个农林系统和每一类生物多样性指标的论文数量。另见所附数字。
理想结果的示范性草图
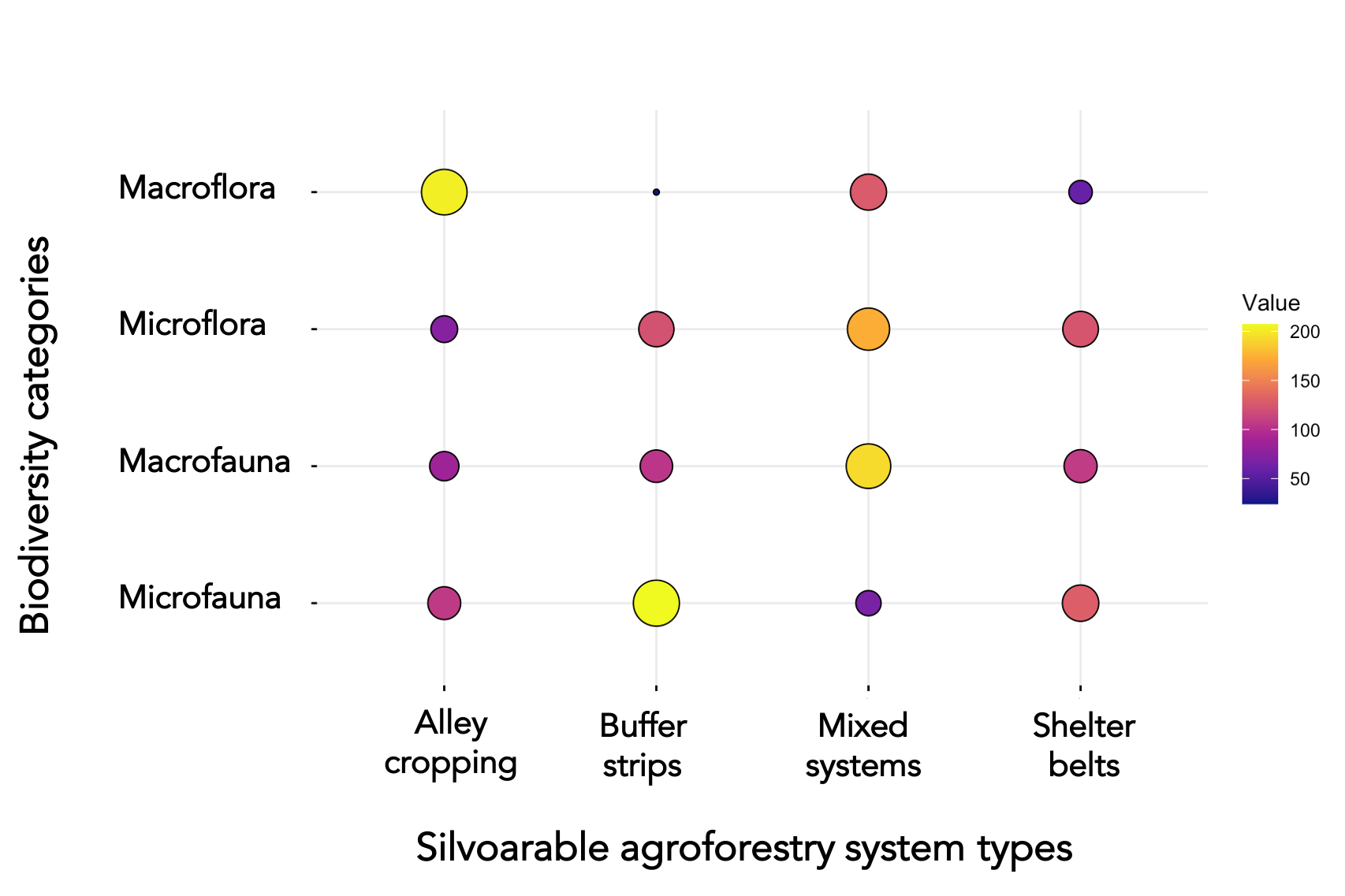
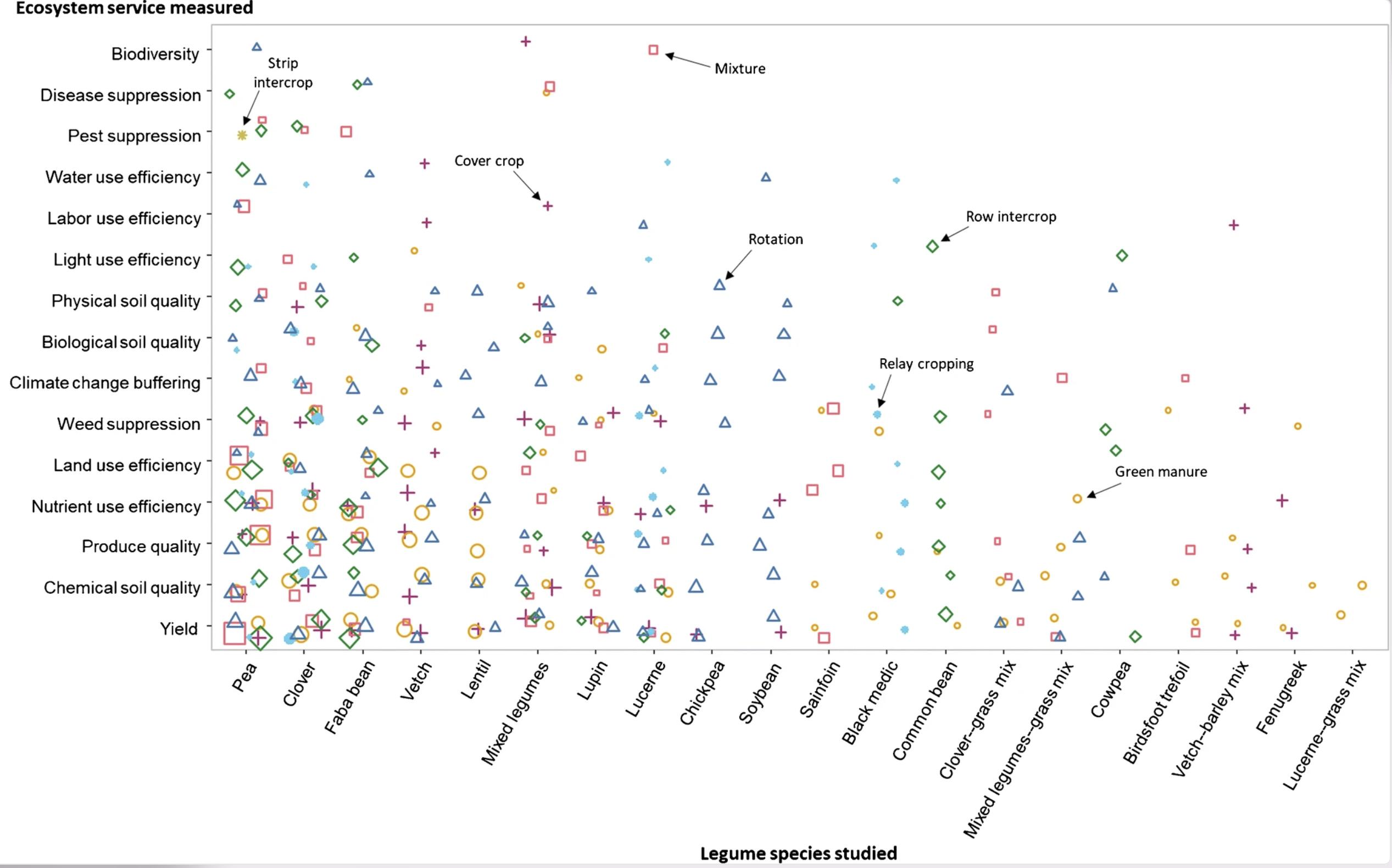
Ditzler等人的鼓舞人心的例子。(2021)
数据
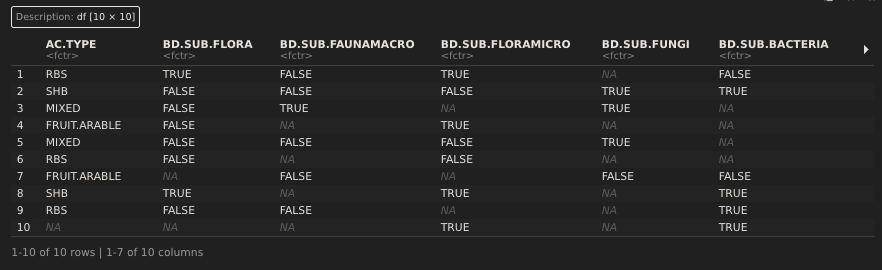
该数据库由数百个变量组成,包括从研究地点到研究中所涉及的具体生物多样性和生态系统服务的所有内容。在这里,我做了一个数据库的子集,它只包含唯一的纸张ID (ID.P)、AC.TYPE (小巷种植类型)和八个生物多样性变量(BD)。
tibble::tribble(
~ID.P, ~ID.S, ~AC.TYPE, ~BD.SUB.FLORA, ~BD.SUB.FAUNAMACRO, ~BD.SUB.FLORAMICRO, ~BD.SUB.FUNGI, ~BD.SUB.BACTERIA, ~BD.SUB.SOILFAUNA, ~BD.SUB.SPEC, ~BD,
24, 4, "NUT.ARABLE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE",
92, 1, "TIMBER.ARABLE", "TRUE", "TRUE", "FALSE", "FALSE", "FALSE", "FALSE", "LANDSCAPE", "TRUE",
99, 9, "SHB", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE",
98, 5, "SHB", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE",
7, 2, "TIMBER.ARABLE", "NA", "NA", "NA", "NA", "NA", "NA", "NA", "FALSE",
125, 1, "BIOMASS.ARABLE", "NA", "NA", "NA", "NA", "NA", "NA", "NA", "FALSE",
45, 17, "NUT.ARABLE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE",
47, 2, "BIOMASS.ARABLE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE",
69, 2, "TIMBER.ARABLE", "FALSE", "FALSE", "TRUE", "TRUE", "TRUE", "TRUE", "MICROBIO.BIOMASS", "TRUE",
14, 1, "TIMBER.ARABLE", "NA", "NA", "NA", "NA", "NA", "NA", "NA", "FALSE",
12, 7, "BIOMASS.ARABLE", "TRUE", "FALSE", "TRUE", "FALSE", "FALSE", "FALSE", "FALSE", "TRUE",
51, 1, "BIOMASS.ARABLE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE",
169, 1, "NA", "NA", "NA", "NA", "NA", "NA", "NA", "NA", "FALSE",
94, 7, "TIMBER.ARABLE", "TRUE", "TRUE", "FALSE", "FALSE", "FALSE", "FALSE", "LANDSCAPE", "TRUE",
49, 1, "TIMBER.ARABLE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE",
99, 1, "SHB", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE",
131, 1, "MIXED", "NA", "NA", "NA", "NA", "NA", "NA", "NA", "FALSE",
45, 13, "FRUIT.ARABLE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE", "FALSE",
152, 1, "BIOMASS.ARABLE", "NA", "NA", "NA", "NA", "NA", "NA", "NA", "FALSE",
37, 29, "NA", "NA", "NA", "NA", "NA", "NA", "NA", "NA", "FALSE"
) 问题
我的问题是,我不能将我的数据转换成所需的格式来生成我想要创建的图形矩阵。我尝试过使用xtabs()和aggregate()函数来创建一个应急矩阵(也称为交叉表),但没有成功(见下文)。我认为这是因为我的数据是基于二进制TRUE/FALSE的。
CrossTab_AC.TYPE_BD <-
xtabs(~ AC.TYPE + BD.SUB.FLORA + BD.SUB.FAUNAMACRO + BD.SUB.FAUNAMACRO + BD.SUB.FLORAMICRO + BD.SUB.FUNGI + BD.SUB.BACTERIA + BD.SUB.SOILFAUNA + BD.SUB.SPEC + BD,
data = BD_database) %>%
as.data.frame.table()
CrossTab_AC.TYPE_BD %>%
sample_n(20) %>%
head(10)
然后,我尝试使用ggballoonplot()绘制数据格式。
ggballoonplot(CrossTab_AC.TYPE_BD, x = "AC.TYPE", y = "BD.SUB.FAUNAMACRO",
size = "Freq", fill = "Freq") +
scale_fill_gradientn(colors = my_cols_pal_10) +
guides(size = FALSE)
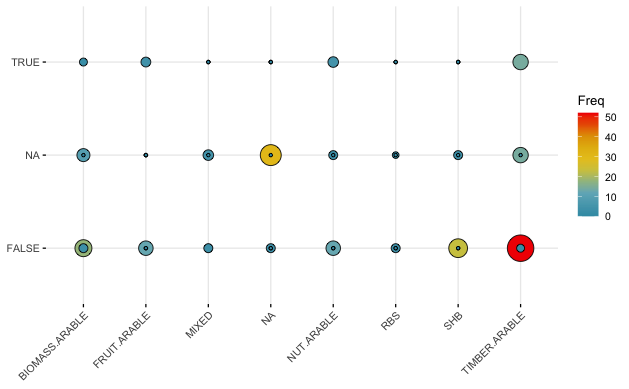
不幸的是,这不管用..。
相反,我应该有一种数据格式,就像他们在那个ggballoonplot示例中使用的那样:
car_data
#> Car Color Value
#> 1 bmw red 86.2
#> 2 renault red 193.5
#> 3 mercedes red 104.2
#> 4 seat red 107.8
#> 5 bmw white 202.9
#> 6 renault white 127.7
#> 7 mercedes white 24.1
#> 8 seat white 58.8
#> 9 bmw silver 73.3
#> 10 renault silver 173.4
#> 11 mercedes silver 121.6
#> 12 seat silver 124.0
#> 13 bmw green 106.6
#> 14 renault green 66.6
#> 15 mercedes green 207.2
#> 16 seat green 129.9
ggballoonplot(car_data, x = "Car", y = "Color",
size = "Value", fill = "Value") +
scale_fill_gradientn(colors = my_cols) +
guides(size = FALSE)
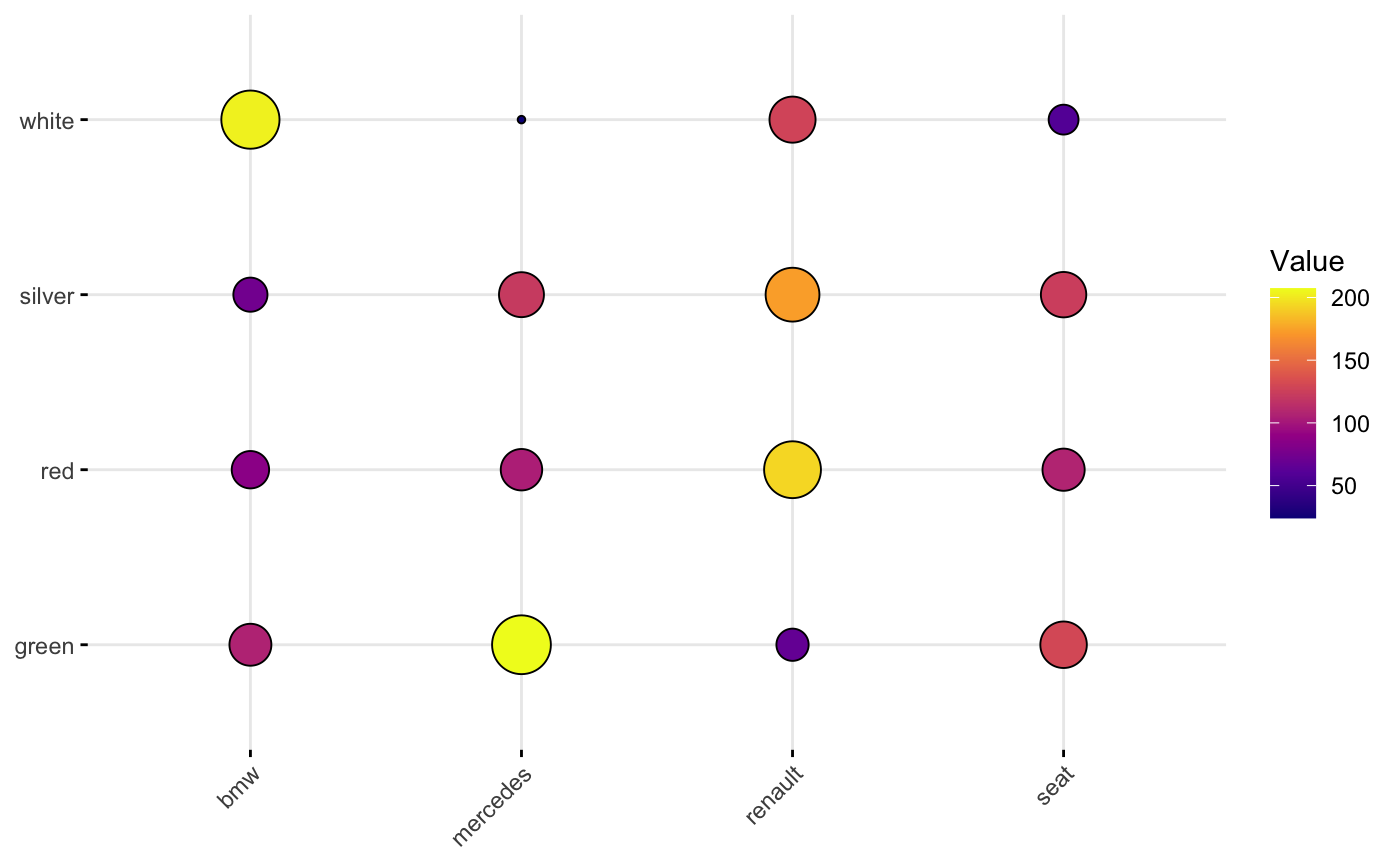
因此,在我看来,真正的问题似乎是如何将二进制真/假数据集转换为某种摘要版本,从而使我能够将其绘制为图形矩阵。
我在这里查看了StackOverflow上的其他帖子,例如,在R]6中用一个图可视化交叉表。
拜托,任何帮助都是非常感谢的!
回答 1
Stack Overflow用户
发布于 2022-08-02 09:24:10
我通过精炼Quinten.的答案找到了解决我的问题的方法
下面是我对生态系统服务的方法,基本上和我想要的生物多样性指标是一样的。
首先,我决定将图形矩阵画成ggplot,而不是ggbalon图,因为输出似乎更容易使我争吵起来,使之变得整洁。
其次,我在pivot_longer()操作中添加了一个pivot_longer()部分,其中包含组AC.TYPE的参数和名称(生态系统服务指示符,ES)。
第三,我总结了AC.TYPE - ES对的出现(对于TRUE ),因为把TRUE改为1只会计数1,而忽略零。
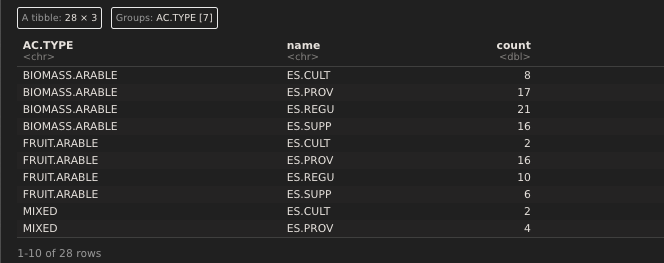
try <-
ES_database %>%
filter(AC.TYPE != "NA") %>%
select(-c(ES)) %>%
pivot_longer(cols = -AC.TYPE) %>%
mutate(value = case_when(value == "TRUE" ~ 1,
value == "FALSE" ~ 0)) %>%
group_by(AC.TYPE, name) %>%
summarize(count = sum(value))这给了我一个数据表:
现在,我可以使用以下代码行使用ggplot()来绘制它:
ggplot(try, aes(x = AC.TYPE, y = name)) +
geom_point(aes(size = count), shape = 21, colour = "black", fill = "cornsilk") +
scale_size_area(max_size = 20, guide = "none")
特别感谢@Quinten,他一直很有帮助!
https://stackoverflow.com/questions/73197280
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号