
如何用正确的dtype逐行构建DataFrame?
我有一个逐行构建的DataFrame (根据需要)。我的问题是,最终,所有的dtypes都是object。如果同时使用所有数据创建DataFrame,则情况并非如此。
让我解释一下我的意思。
import pandas as pd
from IPython.display import display
# Example data
cols = ['P/N','Date','x','y','z']
PN = ['10a1','10a2','10a3']
dates = pd.to_datetime(['2022-07-01','2022-07-03','2022-07-05'])
xd = [0,1,2]
yd = [1.1,1.2,1.3]
zd = [-0.8,0.,0.8]
# Canonical way to build DataFrame (if you have all the data ready)
dg = pd.DataFrame({'P/N':PN,'Date':dates,'x':xd,'y':yd,'z':zd})
display(dg)
dg.dtypes这是我得到的。注意正确的dtypes
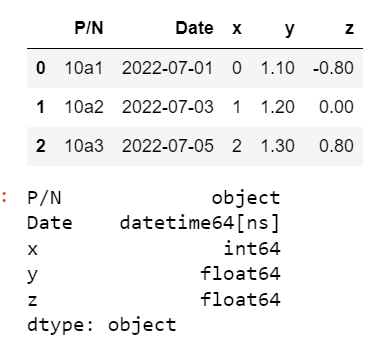
好的,现在我做同样的事情--一行行:
# Build empty DataFrame
cols = ['P/N','Date','x','y','z']
df = pd.DataFrame(columns=cols)
# Add rows in loop
for i in range(3):
new_row = {'P/N':PN[i],'Date':pd.to_datetime(dates[i]),'x':xd[i],'y':yd[i],'z':zd[i]}
# deprecated
#df = df.append(new_row,ignore_index=True)
df = pd.concat([df,pd.DataFrame([new_row])],ignore_index=True)
display(df)
df.dtypes注意[]周围的new_row,否则您会得到一个愚蠢的错误。(我真的不明白append,BTW.它允许有更多可读的代码)
但是现在我明白了:这和上面的不一样,所有的dtypes都是object!
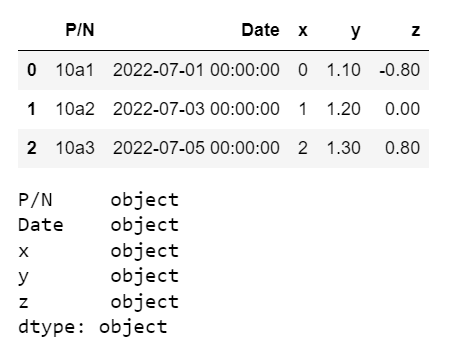
我发现恢复我的dtype的唯一方法是使用infer_objects。
# Recover dtypes by using infer_objects()
dh = df.infer_objects()
dh.dtypes现在dh和dg是一样的。请注意,即使我做了
df = pd.concat([df,pd.DataFrame([new_row]).infer_objects()],ignore_index=True)上面,它仍然不起作用。我认为这是由于concat中的一个bug :当一个空的DataFrame连接到一个非空的DataFrame时,生成的DataFrame无法接管第二个DataFrame的d类型。我们可以通过以下方式验证这一点:
pd.concat([pd.DataFrame(),df],ignore_index=True).dtypes而所有的dtypes仍然是object。是否有更好的方法来逐行构建DataFrame并自动推断正确的dtype?
回答 1
Stack Overflow用户
发布于 2022-07-29 06:13:29
您的初始dataframe df = pd.DataFrame(columns=cols)列都是object类型,因为它没有数据可从中推断dtype。因此,您需要使用astype设置它们。与@mozway一样,建议使用列表来添加from循环。
我希望这对你有用:
import pandas as pd
cols = ['P/N','Date','x','y','z']
dtypes = ['object', 'datetime64[ns]', 'int64', 'float64', 'float64']
PN = ['10a1','10a2','10a3']
dates = pd.to_datetime(['2022-07-01','2022-07-03','2022-07-05'])
xd = [0,1,2]
yd = [1.1,1.2,1.3]
zd = [-0.8,0.,0.8]
df = pd.DataFrame(columns=cols).astype({c:d for c,d in zip(cols,dtypes)})
new_rows = []
for i in range(3):
new_row = [PN[i], pd.to_datetime(dates[i]), xd[i], yd[i], zd[i]]
new_rows.append(new_row)
df_new = pd.concat([df, pd.DataFrame(new_rows, columns=cols)], axis=0)
print(df_new)
print(df_new.info())输出:
P/N Date x y z
0 10a1 2022-07-01 0 1.1 -0.8
1 10a2 2022-07-03 1 1.2 0.0
2 10a3 2022-07-05 2 1.3 0.8
<class 'pandas.core.frame.DataFrame'>
Int64Index: 3 entries, 0 to 2
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 P/N 3 non-null object
1 Date 3 non-null datetime64[ns]
2 x 3 non-null int64
3 y 3 non-null float64
4 z 3 non-null float64
dtypes: datetime64[ns](1), float64(2), int64(1), object(1)
memory usage: 144.0+ byteshttps://stackoverflow.com/questions/73162004
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号