
数据转换列上的部分行数据
数据转换列上的部分行数据
提问于 2022-07-26 18:12:28
我有一个数据,其中的格式,如下图所示。三列表示为一种数据类型的每一行。在给定的示例中,有一列用于滴答,下三列是类,一种是数据类型,5-7列是第二种数据类型。现在,我想在列中转换这一点,在列中,每个类型的数据都由另一个组追加。
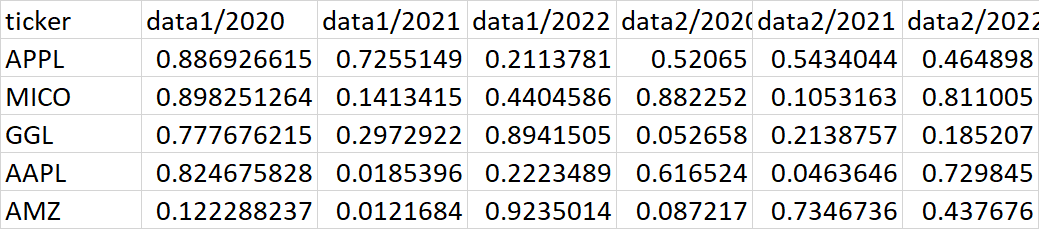
预期产出如下:
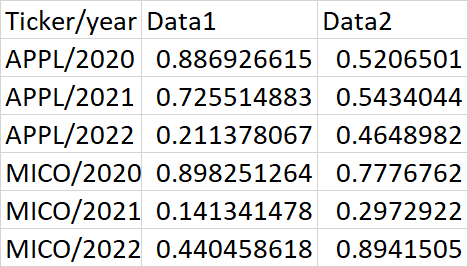
在熊猫身上有使用任何API进行这种转换吗?我正在做这个非常基本的方法,为一个组创建一个新的数据帧,然后附加它。
回答 1
Stack Overflow用户
发布于 2022-07-26 18:43:32
这里有一种方法
使用pd.melt解除表的堆栈,然后在"/“上拆分过去是列(现在作为行),将它们分隔为两列(txt,年份)
通过组合滴答符和年份来创建新的行值,然后使用枢轴获得所需的结果集。
df2=df.melt(id_vars='ticker', var_name='col') # line missed in earlier solution,updated
df2[['txt','year']] = df.melt(id_vars='ticker', var_name='col')['col'].str.split('/', expand=True)
df2.assign(ticker2=df2['ticker'] + '/' + df2['year']).pivot(index='ticker2', columns='txt', values='value').reset_index()结果集
txt ticker2 data1 data2
0 AAPL/2020 0.824676 0.616524
1 AAPL/2021 0.018540 0.046365
2 AAPL/2022 0.222349 0.729845
3 AMZ/2020 0.122288 0.087217
4 AMZ/2021 0.012168 0.734674
5 AMZ/2022 0.923501 0.437676
6 APPL/2020 0.886927 0.520650
7 APPL/2021 0.725515 0.543404
8 APPL/2022 0.211378 0.464898
9 GGL/2020 0.777676 0.052658
10 GGL/2021 0.297292 0.213876
11 GGL/2022 0.894150 0.185207
12 MICO/2020 0.898251 0.882252
13 MICO/2021 0.141342 0.105316
14 MICO/2022 0.440459 0.811005基于您在评论中发布的代码。不幸的是,我在发布解决方案时漏掉了一行。它现在增加了
df2 = pd.DataFrame(np.random.randint(0,100,size=(2, 6)),
columns=["data1/2020","data1/2021", "data1/2022", "data2/2020", "data2/2021", "data2/2022"])
ticker = ['APPL', 'MICO']
df2.insert(loc=0, column='ticker', value=ticker)
df2.head()
df3=df2.melt(id_vars='ticker', var_name='col') # missed line in earlier posting
df3[['txt','year']] = df2.melt(id_vars='ticker', var_name='col')['col'].str.split('/', expand=True)
df3.head()
df3.assign(ticker2=df3['ticker'] + '/' + df3['year']).pivot(index='ticker2', columns='txt', values='value').reset_index()txt ticker2 data1 data2
0 APPL/2020 26 9
1 APPL/2021 75 59
2 APPL/2022 20 44
3 MICO/2020 79 90
4 MICO/2021 63 30
5 MICO/2022 73 91页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73127992
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号