
数据需要切割的Gekko ARX模型
数据需要切割的Gekko ARX模型
提问于 2022-07-24 08:54:43
我习惯于使用商业软件包进行线性模型识别。在这些包中,步骤测试数据的一部分可以标记为坏(例如,当单元发生故障或操作异常时)。我一直在使用Gekko例程提供MPC方法的培训,现在想用它来开发一个项目的模型。我应该做些什么来削减我不想要标识符使用的数据?
回答 1
Stack Overflow用户
发布于 2022-07-26 03:55:10
我建议在处理数据时,使用jupyter笔记本或jupyter实验室。这些备选办法可能有助于:
1-使用熊猫DataFrame:
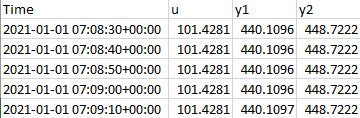
import pandas as pd
df = pd.read_csv('signal_df.csv')
df
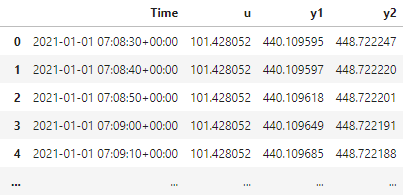
df[['y1', 'y2']].plot()
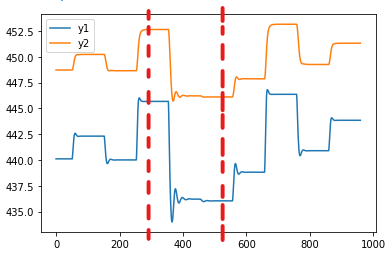
df[['y1', 'y2']].drop(df.index[290:521]).dropna().plot()
2-使用SysID应用程序(基于Gekko):
pip install seeq-sysid从以下位置下载sysid_notebook.ipynb笔记本:
https://github.com/BYU-PRISM/Seeq/tree/main/SysID%20Addon
运行笔记本使用木星笔记本(AppMode),木星实验室或VSCode。
现在,您可以将结果作为一个gekko模型导入:
阅读更多信息:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73096972
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号