
不含硒的抓取介质的clap数据
不含硒的抓取介质的clap数据
提问于 2022-07-22 15:29:15
我试图从中型假设这是链接中抓取拍手数据。当我检查这张照片的时候。
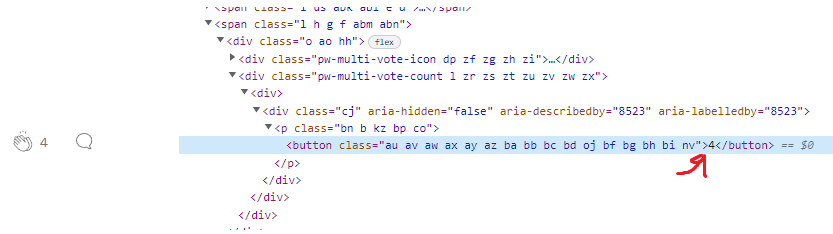
我的代码如下所示:
URL = "https://medium.com/@xdxxxx4713/basic-settings-of-nginx-aeace532534f"
page = requests.get(URL)
soup = BeautifulSoup(page.content, 'html.parser')
print(soup.prettify())只有--在输出中,应该有鼓掌的值。如果可能的话,我如何在不使用Selenium的情况下刮取clap值?在获得了HTML的值"requests.get(URL)“之后,我可以做剩下的事情。html请求在clap值应该在的位置返回空值。
- 我尝试使用urllib库,但链接中有非ASCII字符。
- 我试过使用BeautifulSoup的findChildren库。
- 我试过使用BeautifulSoup的后代遍历算法。
回答 2
Stack Overflow用户
回答已采纳
发布于 2022-07-22 16:23:32
正如@esqew在命令中提到的那样。这有一个API接口,但对我不起作用。但是我受到API代码的启发。这是我的密码:
aditionalPage = requests.get(pages).content.decode("utf-8")
claps = aditionalPage.split("clapCount\":")[1]
endIndex = claps.index(",")
claps = int(claps[0:endIndex])Stack Overflow用户
发布于 2022-07-23 14:43:23
有可能,尝试下面的代码:
import requests
data = [{"operationName":"ClapCountQuery","variables":{"postId":"aeace532534f"},"query":"query ClapCountQuery($postId: ID!) {\n postResult(id: $postId) {\n __typename\n ... on Post {\n id\n clapCount\n __typename\n }\n }\n}\n"}]
r = requests.post('https://medium.com/_/graphql', json=data)
print(r.json()[0]['data']['postResult']['clapCount'])这将返回:
4页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73082751
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号