
突触笔记本参考-从笔记本调用Synapse管道
我正试着从突触笔记本上运行一个突触管道,有什么办法吗?
我的synapse管道有参数,如果可以从笔记本上运行,那么如何通过params?
回答 1
Stack Overflow用户
发布于 2022-08-02 03:42:17
正如Wbob所建议的那样,我也建议不要这样做(从突触笔记本调用synapse管道),因为火花池。
但是,如果您想尝试一下,可以使用REST以外的其他方法。
在这个过程中,我向synapse管道添加了一个存储事件触发器,它通过使用synapse笔记本代码将写入存储触发。
为此,您需要一个存储帐户和一个空容器。
首先,在synapse中为ADLS Gen2创建一个Gen2链接服务,并为synapse管道创建一个存储事件触发器。
在Synapse笔记本中,向ADLS写入一个json文件,这将触发管道。您可以使用相同的json从synapse笔记本中传递参数。
带有示例参数的同步笔记本中的代码:
from pyspark.sql.types import *
myjson=[{"Name":"Rakesh","Age":22,"Marks":90}]
schema2=StructType([StructField('Name',StringType(),True),StructField('Age',IntegerType(),True),StructField('Marks',IntegerType(),True)])
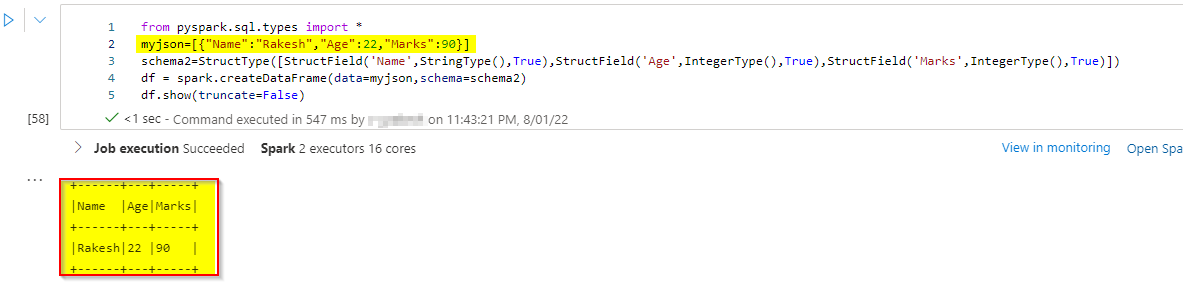
df = spark.createDataFrame(data=myjson,schema=schema2)
df.show(truncate=False)
df2=df.toPandas()
df2.reset_index().to_json('abfss://input/myjson.json', storage_options = {'linked_service' : 'AzureDataLakeStorage1'},orient='records')
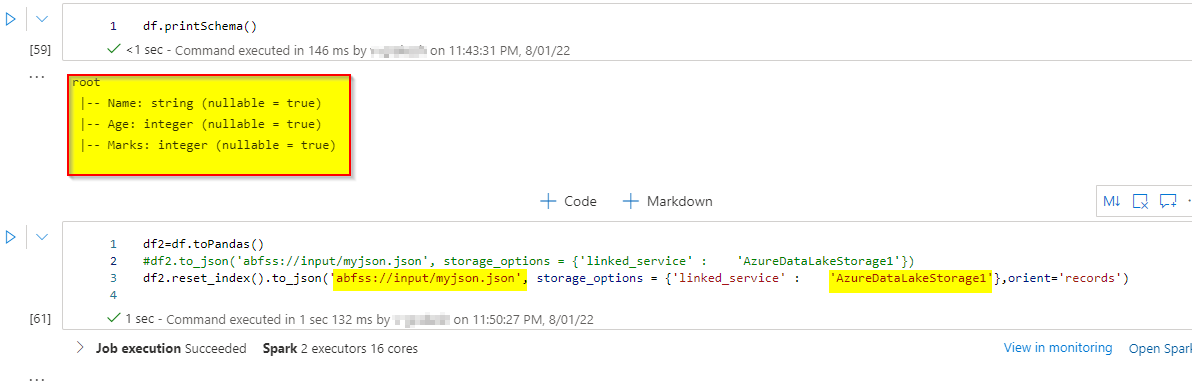
这里,input是我的容器,AzureDataLakeStorage1是我的链接服务。orient='records'给出了带有参数的索引。
这将在ADLS容器中创建myjson.json文件,如下所示。
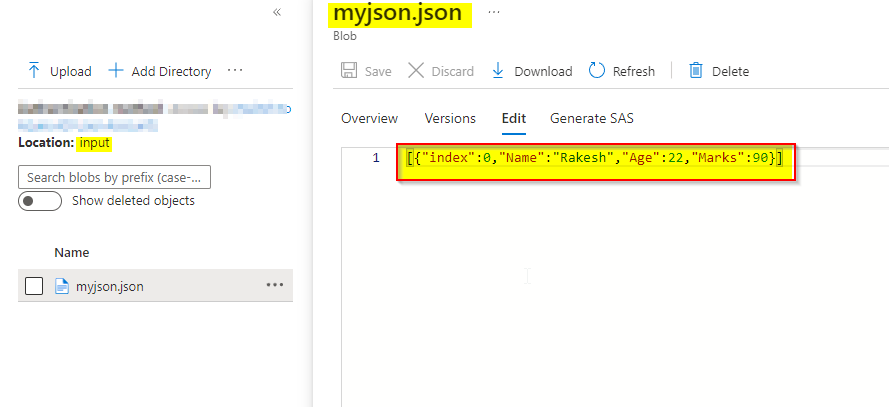
上面的文件触发Synapse管道。若要使用我们传递的参数,请使用管道中的查找活动。
查找活动:
在查找中,不要在数据集中提供任何数据集值。将通配符路径文件设为*.json。
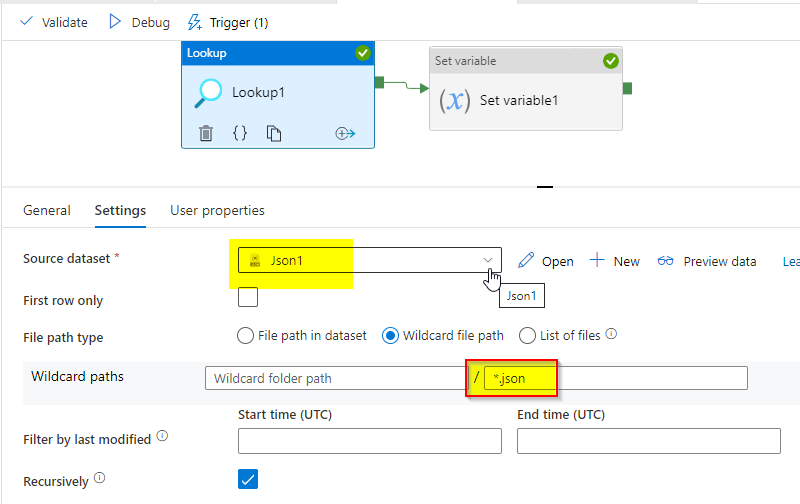
查找结果如下:
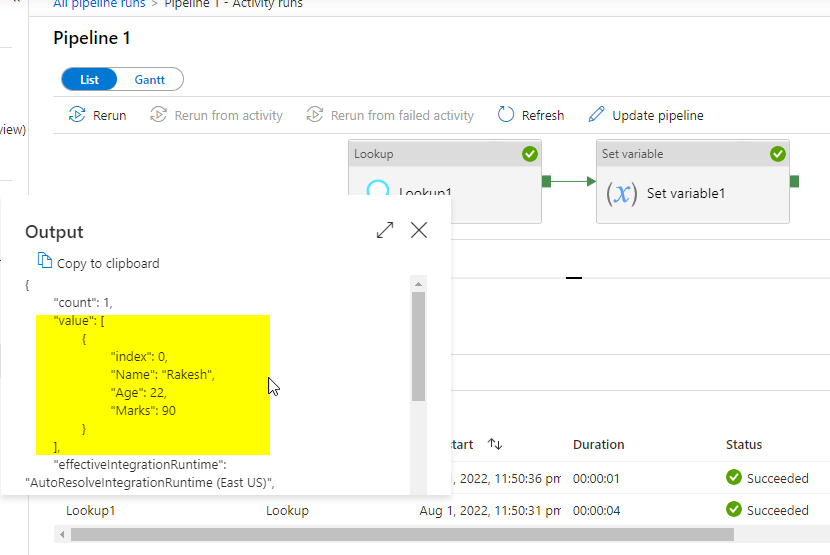
您可以像这样使用表达式@activity('Lookup1').output.value[0].Age和@activity('Lookup1').output.value[0].Name来访问这些参数,并在synapse管道中使用它们自己的数据类型。
例如,set变量活动中的:
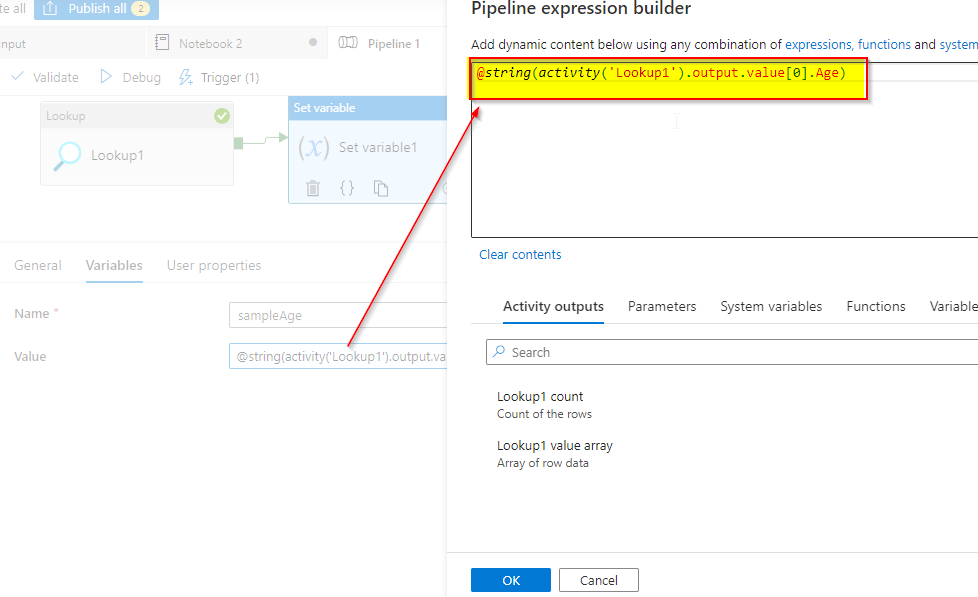
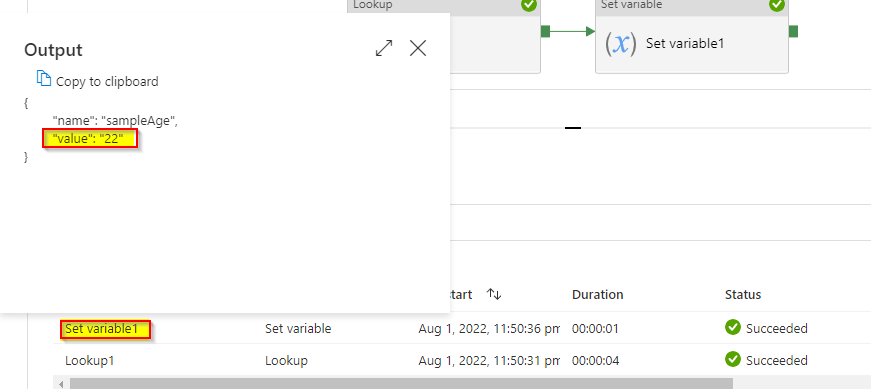
输出:
由于变量只支持string、Booleans和数组,因此我将其转换为string以显示输出。您可以在任何地方使用这些参数。
https://stackoverflow.com/questions/73079287
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号