
熊猫:在多个柱体上制作有熔体的替代行
熊猫:在多个柱体上制作有熔体的替代行
提问于 2022-07-21 09:35:08
说我有数据
data_dict = {'Number': {0: 1, 1: 2, 2: 3}, 'mw link': {0: 'SAM3703_2SAM3944 2', 1: 'SAM3720_2SAM4115 2', 2: 'SAM3729_2SAM4121_ 2'}, 'site_a': {0: 'SAM3703', 1: 'SAM3720', 2: 'SAM3729'}, 'name_a': {0: 'Chelak', 1: 'KattakurganATC', 2: 'Payariq'}, 'site_b': {0: 'SAM3944', 1: 'SAM4115', 2: 'SAM4121'}, 'name_b': {0: 'Turkibolo', 1: 'Kattagurgon Sement Zavod', 2: 'Payariq Dehgonobod'}, 'distance km': {0: 3.618, 1: 7.507, 2: 9.478}, 'manufacture': {0: 'ZTE NR 8150/8250', 1: 'ZTE NR 8150/8250', 2: 'ZTE NR 8150/8250'}}
df = pd.DataFrame(data_dict)

预期输出:
有这两列site_a和site_b,我想把它们合并成行,但是应用简单的熔体就可以串联输出,我希望它们是交替的。
Number mw link distance km manufacture variable value
0 1 SAM3703_2SAM3944 2 3.618 ZTE NR 8150/8250 site_a SAM3703
1 1 SAM3703_2SAM3944 2 3.618 ZTE NR 8150/8250 site_b SAM3944
2 2 SAM3720_2SAM4115 2 7.507 ZTE NR 8150/8250 site_a SAM3720
3 2 SAM3720_2SAM4115 2 7.507 ZTE NR 8150/8250 site_b SAM4115
4 3 SAM3729_2SAM4121_ 2 9.478 ZTE NR 8150/8250 site_a SAM3729
5 3 SAM3729_2SAM4121_ 2 9.478 ZTE NR 8150/8250 site_b SAM4121我的解决方案:
这就是我试过的
df1 = pd.melt(df, id_vars=['Number', 'mw link', 'distance km', 'manufacture'], value_vars=['site_a', 'site_b'])这给了我:
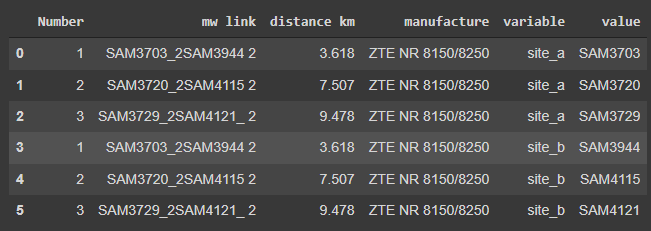
回答 1
Stack Overflow用户
发布于 2022-07-21 09:47:03
你只需添加sort_values(['Number', 'variable'])
pd.melt(df, id_vars=['Number', 'mw link', 'distance km', 'manufacture'], value_vars=['site_a', 'site_b']).sort_values(['Number', 'variable'])

替代办法:
pd.melt(df, id_vars=['Number', 'mw link', 'distance km', 'manufacture'], value_vars=['site_a', 'site_b']).sort_values(['mw link', 'variable'])或者:
pd.melt(df, id_vars=['Number', 'mw link', 'distance km', 'manufacture'], value_vars=['site_a', 'site_b']).sort_values(['distance km', 'variable'])页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73063868
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号