
如何在顶点AI工作台木星实验室笔记本上启动火花会议?
如何在顶点AI工作台木星实验室笔记本上启动火花会议?
提问于 2022-07-20 06:48:34
你能告诉我如何在Google顶点AI工作台木星实验室笔记本上启动火花会议吗?
顺便说一句,这在谷歌公司是很好的。
这里少了什么?
# Install Spark NLP from PyPI
!pip install -q spark-nlp==4.0.1 pyspark==3.3.0
import os
import sys
# https://github.com/jupyter/jupyter/issues/248
os.environ["JAVA_HOME"] = "C:/Program Files/Java/jdk-18.0.1.1"
os.environ["PATH"] = os.environ["JAVA_HOME"] + "/bin:" + os.environ["PATH"]
import sparknlp
from sparknlp.base import *
from sparknlp.common import *
from sparknlp.annotator import *
from pyspark.ml import Pipeline
from pyspark.sql import SparkSession
import pandas as pd
spark=sparknlp.start()
print("Spark NLP version: ", sparknlp.version())
print("Apache Spark version: ", spark.version)
spark

UPDATE_2022-07-21:
嗨@萨扬。在运行命令=(
# Install Spark NLP from PyPI
!pip install -q spark-nlp==4.0.1 pyspark==3.3.0
import os
# Included else "JAVA_HOME is not set"
# https://github.com/jupyter/jupyter/issues/248
os.environ["JAVA_HOME"] = "C:/Program Files/Java/jdk-18.0.1.1"
os.environ["PATH"] = os.environ["JAVA_HOME"] + "/bin:" + os.environ["PATH"]
import sparknlp
spark = sparknlp.start()
print("Spark NLP version: {}".format(sparknlp.version()))
print("Apache Spark version: {}".format(spark.version))错误:
/opt/conda/lib/python3.7/site-packages/pyspark/bin/spark-class: line 71: C:/Program Files/Java/jdk-18.0.1.1/bin/java: No such file or directory
/opt/conda/lib/python3.7/site-packages/pyspark/bin/spark-class: line 96: CMD: bad array subscript
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
/tmp/ipykernel_5831/489505405.py in <module>
6
7 import sparknlp
----> 8 spark = sparknlp.start()
9
10 print("Spark NLP version: {}".format(sparknlp.version()))
/opt/conda/lib/python3.7/site-packages/sparknlp/__init__.py in start(gpu, m1, memory, cache_folder, log_folder, cluster_tmp_dir, real_time_output, output_level)
242 return SparkRealTimeOutput()
243 else:
--> 244 spark_session = start_without_realtime_output()
245 return spark_session
246
/opt/conda/lib/python3.7/site-packages/sparknlp/__init__.py in start_without_realtime_output()
152 builder.config("spark.jsl.settings.storage.cluster_tmp_dir", cluster_tmp_dir)
153
--> 154 return builder.getOrCreate()
155
156 def start_with_realtime_output():
/opt/conda/lib/python3.7/site-packages/pyspark/sql/session.py in getOrCreate(self)
267 sparkConf.set(key, value)
268 # This SparkContext may be an existing one.
--> 269 sc = SparkContext.getOrCreate(sparkConf)
270 # Do not update `SparkConf` for existing `SparkContext`, as it's shared
271 # by all sessions.
/opt/conda/lib/python3.7/site-packages/pyspark/context.py in getOrCreate(cls, conf)
481 with SparkContext._lock:
482 if SparkContext._active_spark_context is None:
--> 483 SparkContext(conf=conf or SparkConf())
484 assert SparkContext._active_spark_context is not None
485 return SparkContext._active_spark_context
/opt/conda/lib/python3.7/site-packages/pyspark/context.py in __init__(self, master, appName, sparkHome, pyFiles, environment, batchSize, serializer, conf, gateway, jsc, profiler_cls, udf_profiler_cls)
193 )
194
--> 195 SparkContext._ensure_initialized(self, gateway=gateway, conf=conf)
196 try:
197 self._do_init(
/opt/conda/lib/python3.7/site-packages/pyspark/context.py in _ensure_initialized(cls, instance, gateway, conf)
415 with SparkContext._lock:
416 if not SparkContext._gateway:
--> 417 SparkContext._gateway = gateway or launch_gateway(conf)
418 SparkContext._jvm = SparkContext._gateway.jvm
419
/opt/conda/lib/python3.7/site-packages/pyspark/java_gateway.py in launch_gateway(conf, popen_kwargs)
104
105 if not os.path.isfile(conn_info_file):
--> 106 raise RuntimeError("Java gateway process exited before sending its port number")
107
108 with open(conn_info_file, "rb") as info:
RuntimeError: Java gateway process exited before sending its port number回答 1
Stack Overflow用户
回答已采纳
发布于 2022-07-21 06:20:07
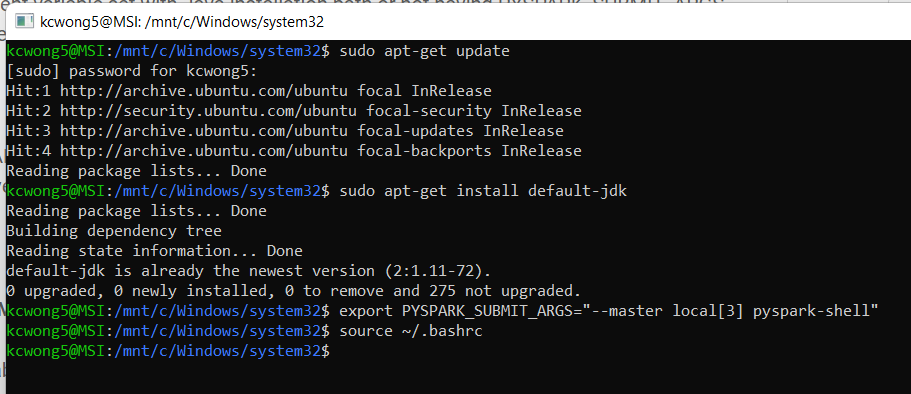
一个可能的原因是没有安装Java。当您创建一个Python-3顶点AI工作台时,您可以使用Debian或Ubuntu作为操作系统,而且它没有预先安装。你需要手动安装它。要安装,可以使用
sudo apt-get update
sudo apt-get install default-jdk您可以按照这个教程安装Open。
所有问题都与安装JDK和在环境中设置它的路径有关。一旦正确地这样做,您也不需要在python中设置路径。您的代码应该如下所示
# Install Spark NLP from PyPI
!pip install -q spark-nlp==4.0.1 pyspark==3.3.0
#no need to set the environment path
import sparknlp
#all other imports
import pandas as pd
spark=sparknlp.start()
print("Spark NLP version: ", sparknlp.version())
print("Apache Spark version: ", spark.version)
spark编辑:--我已经尝试过您的代码了,我所做的相同的error.All是打开工作台的JupyterLab内部的终端,并在那里安装了java。
从工作台打开JupyterLab
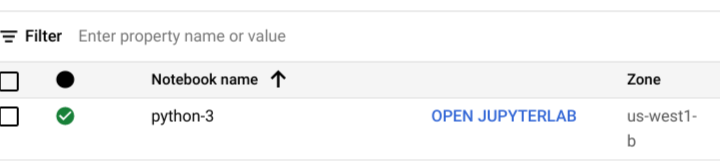
笔记本的例子。
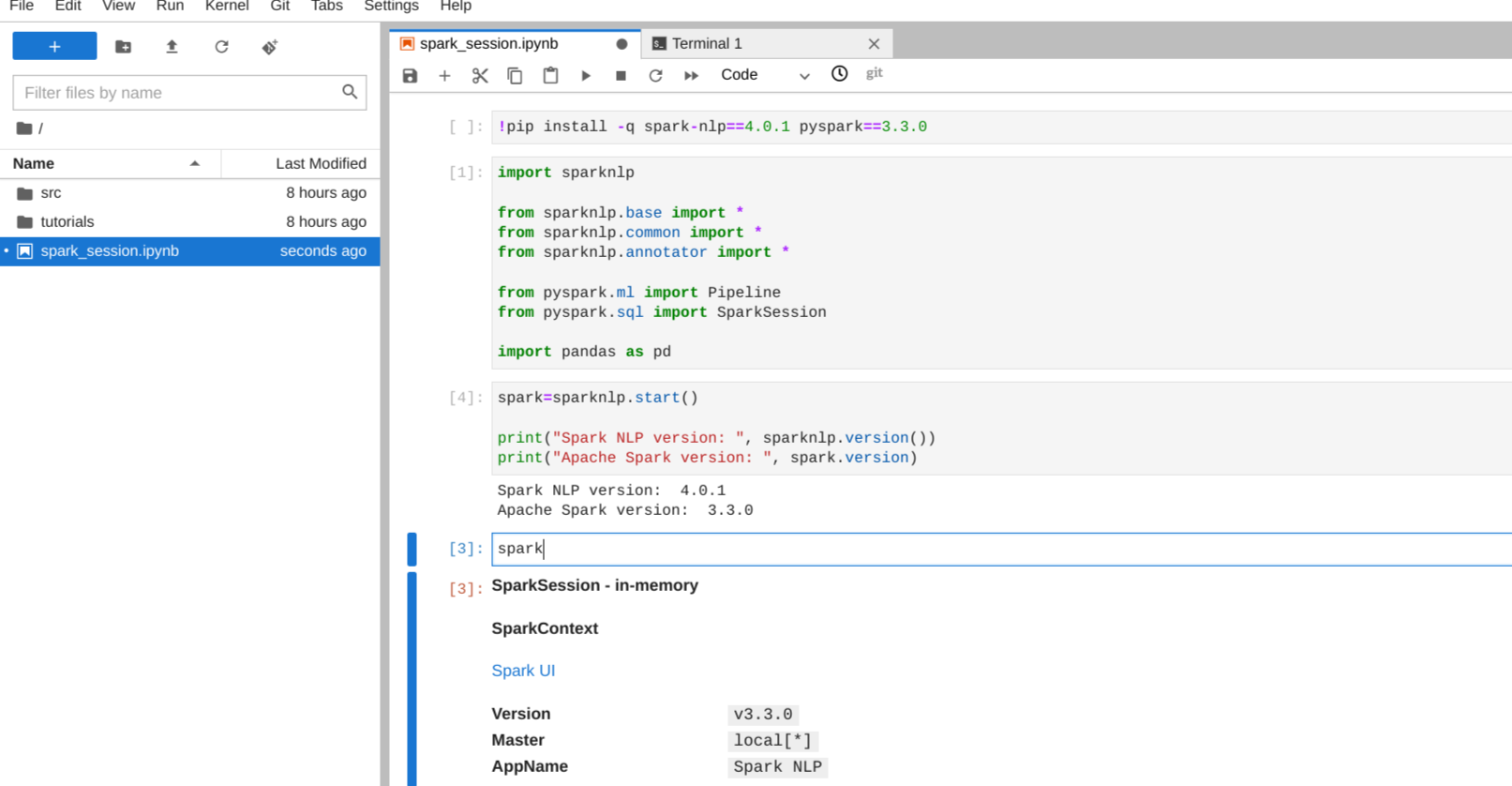
从File->New->Terminal打开终端
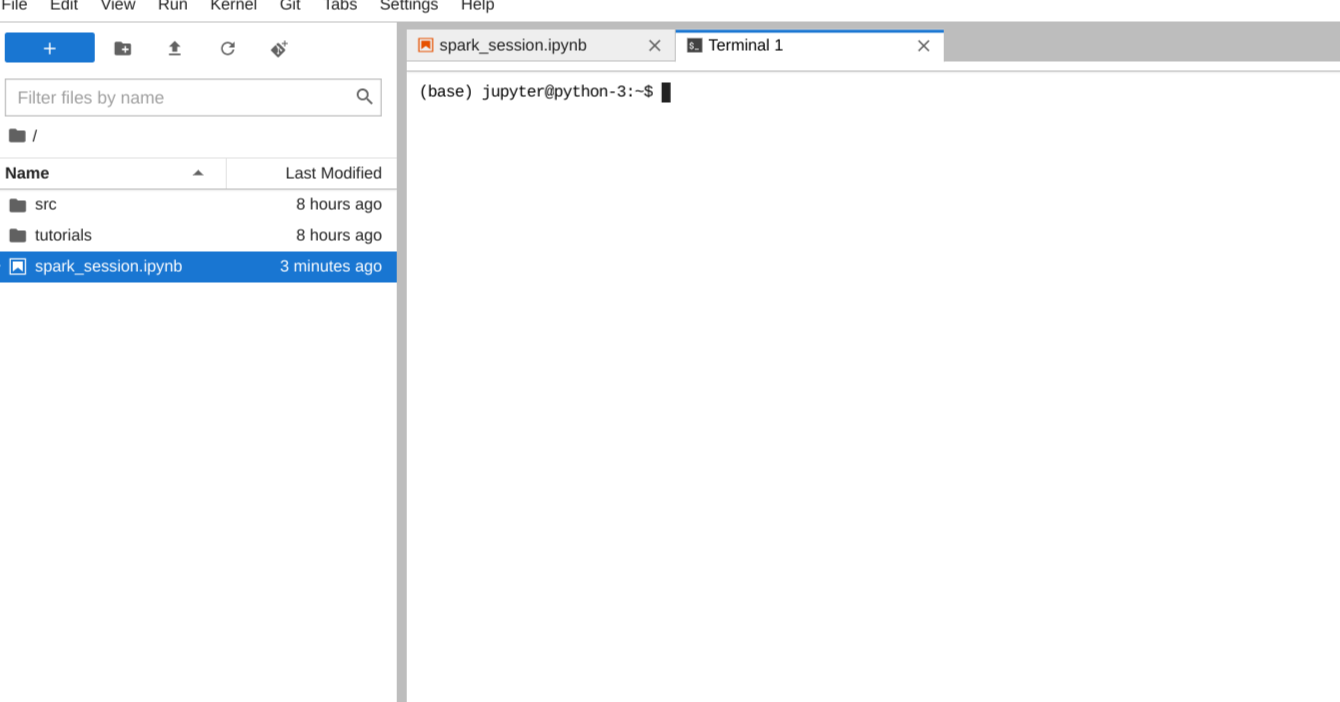
从这里我下载并安装了Java。
您可以通过运行java --version来检查它是否已安装并添加到您的路径中,它将返回当前版本。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73047089
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号