
解栈2列,一个列有列名,另一个列值为多列-熊猫
解栈2列,一个列有列名,另一个列值为多列-熊猫
提问于 2022-07-12 03:10:07
我有一个dataframe,其中"Name“列包含应该构成列名的数据,"Value”列具有相应的值:
Id set Name Value
6050 256 Main_id 5677002
6050 256 Secondary_id 34248
6050 256 Quantity 6
6050 256 warranty Date 4/1/2018
6050 256 Type AB12
6050 256 Value crypt
6050 256 Category DFR
6050 256 Capacity 100
6050 256 Type AB13
6050 256 Value crypt
6050 256 Category BAS
6050 256 Capacity 500
6050 256 Start Date 4/1/2022
6050 256 End Date 1/31/2023
123 456 Main_id 123456789
123 456 Secondary_id 101112131
123 456 Quantity 4
123 456 Type AB12
123 456 Value crypt
123 456 Category DFR
123 456 Capacity 100
123 456 Quantity 5
123 456 warranty Date 4/1/2017
123 456 Type MAC12
123 456 Value crypt
123 456 Category DFR
123 456 Capacity 100
123 456 Start Date 4/1/2022
123 456 End Date 1/31/2023
897 956 Main_id gy4567890
897 956 Secondary_id ky234248
897 956 Quantity 6
897 956 Type MAB13
897 956 Value nocl
897 956 Category gcl
897 956 Capacity 100
897 956 Start Date 4/1/2022
897 956 End Date 1/31/2023需要产出:

对于每一组it以及开始日期和结束日期,它总是以“数量”开头,以“容量”结尾,并在一个或多个类型之间结束。任何数据丢失的地方都应该留空。如果有多个“类型”表示“数量”(和/或“保证日期”),则会重复。
这不适用于这个数据格式。
df_.pivot_table(index=["Id", "set"],
columns='Name',
values='Value',
aggfunc=', '.join).reset_index().rename_axis(None, axis=1)任何帮助或建议都是非常感谢的。
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-07-12 04:01:53
这里有一种方法
使用“赋值”创建临时列,以消除枢轴中的重复错误,然后删除该列
df.assign(
dup=df.groupby(['Id', 'Name']).cumcount()
).pivot(
index=['Id','set','dup'],
columns='Name',
values='Value').reset_index().drop(columns='dup')
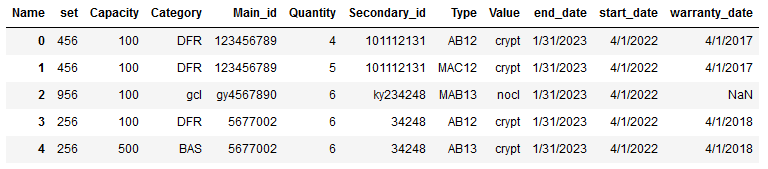
若要使用相同id的前面的值填充空值,请执行以下操作
df2=df.assign(
dup=df.groupby(['Id', 'Name']).cumcount()
).pivot(
index=['Id','set','dup'],
columns='Name',
values='Value').reset_index()
df2.groupby('Id').fillna(method='ffill').drop(columns='dup')
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72946632
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号