
del [dataframe]与`del dataframe‘有何不同?
我在看Python代码库的内存消耗。这个代码库利用pandas和numpy来操纵巨大的数据帧。
当我们完成中间数据表示时,我们希望释放它来释放一些内存。我的一位同事注意到调用del dataframe和del [[dataframe]]是有区别的
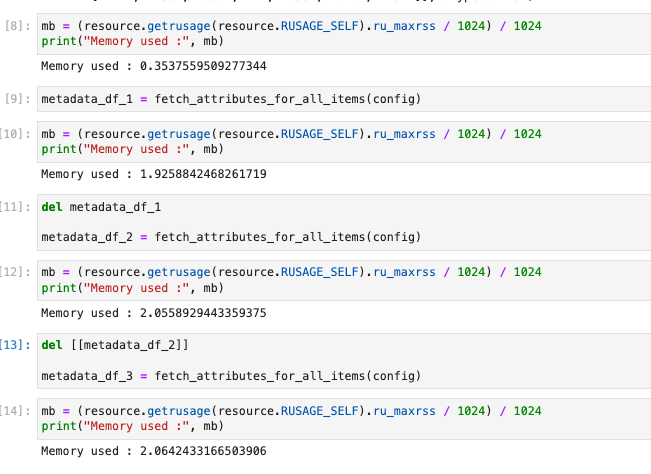
他们由此得出结论:“如果del df和del [[df]]做同样的事情,那么来自单元格12的内存应该与单元格10中的内存相同,介于12到14之间,但是您可以看到,并不是所有的内存都被释放出来重新使用。”
我同意他们对实践逻辑中发生的事情的理解。然而,当我试图建立一个理论上的理解来支持这些代码时,我无法清楚地解释为什么这会有所不同。
查看this answer,使用target_list的del语句的定义应该使del my_list和target_list等效:
del_stmt ::= "del" target_list然而在this answer中,作者使用的是del [[df1, df2]]而不是del df1, df2,甚至是del [df1, df2]。
更糟糕的是,this answer甚至说了相反的话:“如果您只是添加到列表中,它就不会删除原始的dataframe,当您删除该列表时”,并得出结论认为应该更喜欢del df1而不是del [df1]。
如果语言定义表明对del的调用是相同的,那么它们之间又有什么区别呢?
回答 1
Stack Overflow用户
发布于 2022-07-07 09:28:13
从字面上讲,两者没有任何区别。他们也做同样的事。它们甚至编译成完全相同的字节码:
In [1]: import dis
In [2]: dis.dis('del x')
1 0 DELETE_NAME 0 (x)
2 LOAD_CONST 0 (None)
4 RETURN_VALUE
In [3]: dis.dis('del [x]')
1 0 DELETE_NAME 0 (x)
2 LOAD_CONST 0 (None)
4 RETURN_VALUE
In [4]: dis.dis('del [[x]]')
1 0 DELETE_NAME 0 (x)
2 LOAD_CONST 0 (None)
4 RETURN_VALUE您看到的结果很可能是由于执行顺序效应造成的。
https://stackoverflow.com/questions/72895344
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号