
计算一棵树中花费0模k的所有路径。
我有一棵树,现在我想数到树根的路径数,(它不需要到达根节点)。
在计算路径时,我希望找到该路径的成本,并以(成本%k= 0)的形式进行计算,以找到所有这样的有效路径。
对于输入k=2和list = 1,1,1,1,from = 1,1,4,to = 2,4,3列表表示每个节点的成本。从和表示树中的边缘。
这棵树表现为:
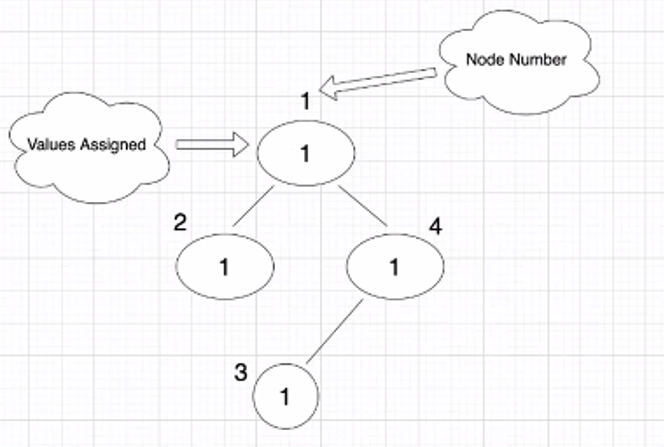
对于上面的树,我们有8条可能的路径:
1
2
4
2->1
4->1
3
3->4 (this has a path that can reach root node, so this path is considered)
3->4->1但只有有效路径是
2->1
4->1
3->4已经花费了%k= 0。结果是3。
这是我的代码,这里我检查从边和边和,并检查余数与k是0,也检查边的余数为0。
public int findValidPaths(List<Integer> list, int nodes, List<Integer> from, List<Integer> to, int k) {
int result = 0;
for(int e : to) {
if(list.get(e-1) % k == 0) {
result++;
}
}
for(int i=0; i<from.size(); i++) {
int cost = list.get(from.get(i)-1) + list.get(to.get(i) -1);
if(cost%k == 0) {
result++;
}
}
return result + 1;
}我的方法是不正确的,因为我没有检查所有的路径,如何解决这个问题。
约束:
cost : 1 to 10^9
k : 1 to 10^5 另一个例子:
投入如下:
list = [1,2,2,1,2], from = [2,2,1,2], to = [3,1,4,5], k = 2
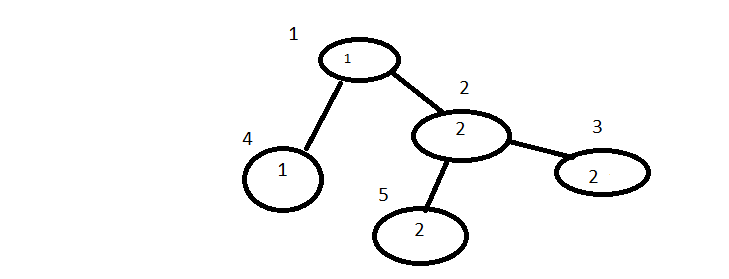
预期的输出为6,因为有效的组合如下:
5
3
2
5-2
3-2
4-1回答 3
Stack Overflow用户
发布于 2022-07-05 19:48:55
一般的O(n)公式可以让f(n)表示从根到根的遍历的前缀和模k所能达到的所有剩馀数。然后,节点n可以与许多与(sum_head + n) % k相同的剩馀部分配对,其中sum_head是前缀和模k,以n的父节点结尾。
为了有效地利用空间,我们可以使用sum mod k -> count映射,递归到树中,并在递归之后取消我们刚刚创建的前缀和(即回溯)。
例如,k = 3
G(2)
/ \
E(1) F(2)
/ \ / \
A(2) B(4) C(2) D(5)前缀和模k = 3
G -> E -> A
2 0 2
-> B
1
G -> F -> C
2 1 0
-> D
0我们到达E,在那里数0前缀和。在A处,我们将2与prefix_sum_mod_k映射中的2匹配,这说明了路径A -> E。
我们回溯,取消a 2和检查B,它在地图上没有匹配。
我们回溯到G,取消1和0,并继续到F,它没有匹配。我们继续到C,这是一个0,并计算它。我们回溯到F,取消一个0,然后继续到D,再数一个0。
共计:4
E -> G
A -> E
C -> F -> G
D -> F -> GPython代码:
from collections import defaultdict
def f(k, costs, from_lst, to_lst):
children = defaultdict(list)
for i, u in enumerate(from_lst):
children[u].append(to_lst[i])
prefixes = defaultdict(int)
prefixes[0] = 1
def g(n, s):
result = 0
curr = (s + costs[n]) % k
result += prefixes[curr]
prefixes[curr] += 1
for c in children[n]:
result += g(c, curr)
prefixes[curr] -= 1
return result
return g(0, 0)输出:
params = [
(3, [2,1,2,2,4,2,5], [0,0,1,1,2,2], [1,2,3,4,5,6]),
(2, [1,1,1,1], [0,0,3], [1,3,2]),
(2, [1,2,2,1,2], [0,0,1,1], [1,3,2,4])
]
for args in params:
print(f(*args), args)
"""
4 (3, [2, 1, 2, 2, 4, 2, 5], [0, 0, 1, 1, 2, 2], [1, 2, 3, 4, 5, 6])
3 (2, [1, 1, 1, 1], [0, 0, 3], [1, 3, 2])
6 (2, [1, 2, 2, 1, 2], [0, 0, 1, 1], [1, 3, 2, 4])
"""Java代码(假设树根标记为1,对两个示例输入都有效):
private static void directTheGraph(
Integer node,
Map<Integer,List<Integer>> children) {
if (children.containsKey(node)) {
for (Integer child : children.get(node)) {
if (children.containsKey(child)) {
children.get(child).remove(node);
}
}
for (Integer child : children.get(node)) {
directTheGraph(child, children);
}
}
}
private static long g(
Integer node,
Integer sum,
List<Integer> costs,
Map<Integer,Integer> prefixes,
Map<Integer,List<Integer>> children,
int k) {
long result = 0;
Integer curr = (sum + costs.get(node-1)) % k;
result += prefixes.getOrDefault(curr, 0);
if (prefixes.containsKey(curr)) {
prefixes.put(curr, prefixes.get(curr) + 1);
} else {
prefixes.put(curr, 1);
}
if (children.containsKey(node)) {
for (Integer child : children.get(node)) {
result += g(child, curr, costs, prefixes, children, k);
}
}
prefixes.put(curr, prefixes.get(curr) - 1);
return result;
}
private static long f(
List<Integer> costs,
List<Integer> from,
List<Integer> to,
int k) {
Map<Integer, List<Integer>> children = new HashMap<>();
for (int i = 0; i < from.size(); i++) {
Integer u = from.get(i);
Integer v = to.get(i);
if (children.containsKey(u)) {
children.get(u).add(v);
} else {
children.put(u, new ArrayList<>());
children.get(u).add(v);
}
if (children.containsKey(v)) {
children.get(v).add(u);
} else {
children.put(v, new ArrayList<>());
children.get(v).add(u);
}
}
directTheGraph(1, children);
Map<Integer, Integer> prefixes = new HashMap<>();
prefixes.put(0, 1);
return g(
1,
0,
costs,
prefixes,
children,
k);
}
public static void main (String[] args) throws java.lang.Exception {
List<Integer> costs = List.of(1,1,1,1);
List<Integer> from = List.of(1,1,4);
List<Integer> to = List.of(2,4,3);
int k = 2;
System.out.println(f(costs, from, to, k));
costs = List.of(1,2,2,1,2);
from = List.of(2,2,1,2);
to = List.of(3,1,4,5);
k = 2;
System.out.println(f(costs, from, to, k));
}Stack Overflow用户
发布于 2022-07-07 13:40:57
顺便说一下,您的第二个示例变量from的值不正确,因为没有从根(节点1)到任何其他节点的路径(即变量from中不存在值1)。
如果我正确理解了您的问题,您需要将路径成本从下往上,即从叶节点开始,然后一直工作到根部。这比计算从根到叶的总成本要复杂一些。
解决方案要求,对于每个节点,我们首先计算它的父节点(我已经将每个节点重新编号为parent列表中的源-0)。这是一个O(N)操作。这样我们就可以把树从叶节点一直走到根部积累的成本。的确,有些节点(有两个子节点)将被访问两次,但这仍然是一个O(N)操作,因为在最坏的情况下,访问的节点数将小于2*N。
import java.util.ArrayList;
import java.util.HashSet;
public class Test {
public int findValidPaths(int[] list, int[] from, int[] to, int k) {
// Convert passed arguments into a tree:
// Find leaves:
HashSet<Integer> leaves = new HashSet<Integer>();
for (int i: to)
leaves.add(i - 1); // 0-origin
HashSet<Integer> fromSet = new HashSet<Integer>();
for (int i: from)
fromSet.add(i - 1); // 0-origin
leaves.removeAll(fromSet);
int numNodes = list.length;
int[] parent = new int[numNodes];
parent[0] = -1; // root node has no parent
for (int i = 0; i < from.length; i++) {
int fromNode = from[i] - 1; // 0-origin
int toNode = to[i] - 1; // 0-origin
parent[toNode] = fromNode;
}
int counter = 0;
int nodesVisited = 0;
for (int nodeNumber: leaves) {
int totalCost = 0;
while (nodeNumber != -1) {
nodesVisited += 1;
totalCost += list[nodeNumber];
if (totalCost % k == 0)
counter += 1;
nodeNumber = parent[nodeNumber];
}
}
System.out.printf("Total nodes: %d, Nodes visited: %d\n", numNodes, nodesVisited);
return counter;
}
public void test1() {
int[] list = {1, 1, 1, 1};
int[] from = {1, 1, 4};
int[] to = {2, 4, 3};
int n = findValidPaths(list, from, to, 2);
System.out.printf("Number of paths: %d\n", n);
}
public void test2() {
int[] list = {1,2,2,1,2};
int[] from = {1,1,2,2};
int[] to = {2,4,3,5};
int n = findValidPaths(list, from, to, 2);
System.out.printf("Number of paths: %d\n", n);
}
public void test3() {
/*
1
/
2
/
2
*/
int[] list = {1,2,2};
int[] from = {1,2};
int[] to = {2,3};
int n = findValidPaths(list, from, to, 2);
System.out.printf("Number of paths: %d\n", n);
}
public static void main(String[] args) {
Test test = new Test();
test.test1();
test.test2();
test.test3();
}
}指纹:
Total nodes: 4, Nodes visited: 5
Number of paths: 2
Total nodes: 5, Nodes visited: 8
Number of paths: 5
Total nodes: 3, Nodes visited: 3
Number of paths: 2Stack Overflow用户
发布于 2022-07-08 19:11:26
一种方法是将树倒转,并将其视为DAG (有向无圈图),这意味着链接从一个子链接到另一个父图。我们引入了一个源节点,它与所有其他节点都有链接。源和任何其他节点之间的链接是一条路径。
为了找到所有有效的路径,我们从源节点开始递归遍历DAG。在每个节点上,我们使用有效性公式确定它是否是一个有效路径,并使用沿着该路径到该节点的累计成本。递归在前根节点上回滚。
如果我们在递归继续下去时计算有效路径的数量,那么我们可以在不同的分支回绕时从不同的分支中将计数相加,在它结束时以总数结束。
一旦您拥有了DAG,这应该只是几行Java代码。
我使用DAG方法添加了一个Java实现。我首先使它是递归的,但是Java似乎没有优化尾递归,所以我切换到了迭代。我只使用int和int数组来避免int和Integer之间耗时的类型强制.在Java中,代码的速度和Java一样快,这让人联想到C。
具有N个节点的随机二叉树的平均高度复杂度为O(logN),具有很高的概率。如果我们使用它作为平均路径长度的上限,DAG方法将变成O(N*logN)。DAG方法适用于并行执行,使得复杂度下降到O(logN)。实际上,我们没有N个处理器,但是代码变得更快了。
import java.util.Arrays;
class CountPaths {
CountPaths(int K, int[] list, int[] from, int[] to) { // constructor
N = list.length + 1;
this.K = K;
dag = new int[N];
cost = new int[N];
for (int i=0; i<list.length; i++) cost[i+1] = list[i]; // setup costs
for (int i=0; i<to.length; i++) dag[to[i]] = from[i]; // setup DAG
path = new int[N]; // the current path
top = 0; // top of path
}
void go() { // start
System.out.println("K = " + K);
System.out.println("Cost = " + Arrays.toString(cost));
System.out.println("Dag = " + Arrays.toString(dag));
System.out.println("---");
int n = 0; // valid paths
for (int i=1; i<N; i++) { // all paths
top = 0;
n += nodes(i, 0);
System.out.println("---");
}
System.out.println("Valid paths = " + n);
}
final int N, K;
final int[] dag, cost;
int[] path;
int top;
boolean validity(int cost, int K) { // check validity
return (cost % K) == 0;
}
int nodes(int curNode, int accCost) { // iterative processing of nodes
int n = 0; // number of valid paths
while (curNode > 0) {
path[top++] = curNode; // update current path
accCost += cost[curNode]; // accumulated cost
boolean valid = validity(accCost, K); // check validity
if (valid) n++;
System.out.print("Path=" + path[0]);
for (int i=1; i<top; i++) System.out.print("->" + path[i]);
System.out.print(", Cost=" + accCost);
if (valid) System.out.print(", (Valid)");
System.out.println();
curNode = dag[curNode]; // next node in path
}
return n;
}
/*
int nodes(int curNode, int accCost) { // recursive processing of nodes
if (curNode == 0) return 0; // stop criterion
path[top++] = curNode; // update current path
accCost += cost[curNode]; // accumulated cost
boolean valid = validity(accCost, K); // check validity
System.out.print("Path=" + path[0]);
for (int i=1; i<top; i++) System.out.print("->" + path[i]);
System.out.print(", Cost=" + accCost);
if (valid) System.out.print(", (Valid)");
System.out.println();
return (valid ? 1 : 0) + nodes(dag[curNode], accCost); // tail recursive call to next node in path
}
*/
} // CountPaths
public class Main {
public static void main(String[] args) {
int K=2;
int[] list = {1,1,1,1};
int[] from = {1,1,4};
int[] to = {2,4,3};
/* int K=2;
int[] list = {1,2,2,1,2};
int[] from = {2,1,1,2}; // corrected [2,2,1,2] in the example
int[] to = {3,2,4,5}; // corrected [3,1,4,5] in the example
*/
new CountPaths(K, list, from, to).go(); // Construct CountPaths and call go
}
} // Main以下是两次测试的结果:
1.
K = 2
Cost = [0, 1, 1, 1, 1]
Dag = [0, 0, 1, 4, 1]
---
Path=1, Cost=1
---
Path=2, Cost=1
Path=2->1, Cost=2, (Valid)
---
Path=3, Cost=1
Path=3->4, Cost=2, (Valid)
Path=3->4->1, Cost=3
---
Path=4, Cost=1
Path=4->1, Cost=2, (Valid)
---
Valid paths = 3
2.
K = 2
Cost = [0, 1, 2, 2, 1, 2]
Dag = [0, 0, 1, 2, 1, 2]
---
Path=1, Cost=1
---
Path=2, Cost=2, (Valid)
Path=2->1, Cost=3
---
Path=3, Cost=2, (Valid)
Path=3->2, Cost=4, (Valid)
Path=3->2->1, Cost=5
---
Path=4, Cost=1
Path=4->1, Cost=2, (Valid)
---
Path=5, Cost=2, (Valid)
Path=5->2, Cost=4, (Valid)
Path=5->2->1, Cost=5
---
Valid paths = 6https://stackoverflow.com/questions/72859836
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号