
平均色差散射图
我有一个2020年观测数据框架"DF“和79066个变量。第一列是从1到2020年的连续年份,其他列(变量)是数字。
为了重现性,我创建了我伪造的数据框架,从2000年到2020年的20年,只有100个变量。例如:
set.seed(123)
i <- 100
DF <- data.frame(year=c(2000:2020),
setNames(
as.data.frame(lapply(1:i, function(k) c(rnorm(21)))),
paste("Var_", 1:i, sep = "")))然后,我创建了一个逐行的平均值。
DF$Aver <- apply(DF[, 2:101], 1, mean, na.rm=TRUE)然后,我把平均值画成一条线,然后加分。
plot(DF$year, DF$Aver, type="l", col=1, cex=0.5, las=1, xlab="", ylab="", ylim=c(-4, 4))
for (i in 2:101) {
points(DF$year, DF[, i], pch=20, cex=1, col='gray')
}然而,我想要的是一个散点图,其中接近平均值的点是深灰色的,灰色的颜色是向尾端方向的阴影(浅灰)。
回答 1
Stack Overflow用户
发布于 2022-07-02 16:11:34
您可以在迭代中使用normalize变量,并将其用作rgb(red, gree, blue, alpha)函数中的alpha值,其中值介于0,1之间。由于最小值为零α,所以我们只需在非常浅灰色的情况下第二次使用points。
normalize <- function(x, na.rm=FALSE) {
na <- is.na(x)
x[na] <- min(x, na.rm=TRUE)
num <- x - min(x)
denom <- max(x) - min(x)
return(replace(num/denom, na, NA_real_))
}
plot(DF$year, DF$Aver, type="l", col=1, cex=0.5, las=1, xlab="", ylab="", ylim=c(-4, 4))
for (i in 2:101) {
# points(DF$year, DF[, i], pch=20, cex=1, col=rgb(.8, .8, .8, 1 - normalize(abs(DF[, i]))))
points(DF$year, DF[, i], pch=20, cex=1, col=rgb(.8, .8, .8, 1 - {nz <- normalize(abs(DF[, i])); replace(nz, is.na(nz), 0)}))
points(DF$year, DF[, i], pch=20, cex=1, col=rgb(.1, .1, .1, .05))
# points(DF$year, DF[, i], pch=20, cex=1, col='gray')
}
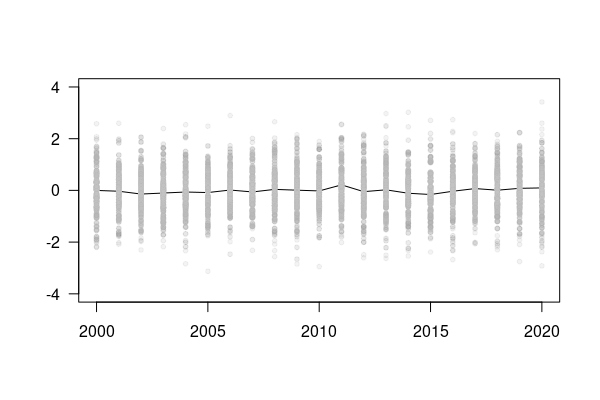
更新
在你的例子中,不可能有像159,713,320这样的大量点数。人眼无法解决这个问题,一个令人讨厌的惊喜可能会在拷贝商店等着我们。
解决这个问题的一个常见方法是使用一个较小的随机sample s来处理size=参数中的一小部分列。(不需要关心整数,sample会舍入reals。)它将充分地表示您的数据。
set.seed(42) ## for sake of reproducibility
s <- sample(2:ncol(DF_huge), size=(ncol(DF_huge) - 1)*.0005) ## see data below无论如何,我们可以使用plot ntype=‘初始化一个空的, since the line will be overlaid from the。
接下来,在用于for的points循环中,我们精确地在这个子集s上迭代。这里有这么多点,我们可以简化为一个单一颜色的'#RRGGBBaa'定义为十六进制格式1-F,其中R=red,G=green,B=blue和a=alpha (不透明度)。我从上面对这种方法进行了评论,但您可能希望两者都尝试一下。
最后,使用lines绘制平均线作为顶层,在这里我们可以使用整个数据集。
plot(DF_huge$year, DF_huge$Aver, type="n", las=1, xlab="", ylab="", ylim=c(-4, 4))
for (i in s) {
v <- .5
# points(DF_huge$year, DF_huge[, i], pch='.', cex=3,
# col=rgb(v, v, v, 1 - {nz <- normalize(abs(DF_huge[, i])); replace(nz, is.na(nz), 0)}))
points(DF_huge$year, DF_huge[, i], pch='.', cex=3, col="#88888833")
}
lines(DF_huge$year, DF_huge$Aver, type="l", col=1, cex=0.5, las=1, xlab="", ylab="", ylim=c(-4, 4))
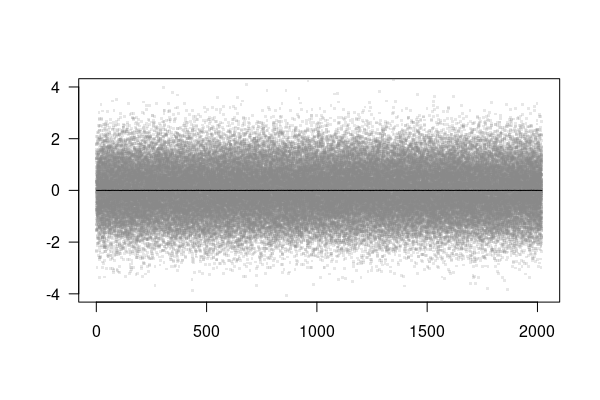
数据:
n <- 2020
m <- 79066
set.seed(42)
Var <- replicate(m, rnorm(n))
Var[sample(seq_along(Var), 2000)] <- NA_real_ ## produce 2000 random missings
DF_huge <- data.frame(year=seq_len(n), Var=Var)
DF_huge$Aver <- rowMeans(DF_huge[-1], na.rm=TRUE) ## much faster than `apply(., mean)`!https://stackoverflow.com/questions/72839856
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号