
在熊猫中将扁平的excel转换为嵌套的json
在熊猫中将扁平的excel转换为嵌套的json
提问于 2022-07-01 14:03:41
我对此相当陌生,花了一整天的时间阅读大量的帖子,并弄清楚如何将这个扁平的excel表转换为嵌套的json。下面是一个扁平嵌套表的示例:
{'Sample': {0: '1A',
1: '1A',
2: '1A',
3: '1A',
4: '1A',
5: '1A',
6: '1A',
7: '2A',
8: '2A',
9: '2A',
10: '2A',
11: '2A',
12: '2A',
13: '2A'},
'Substance category': {0: 'Additive',
1: 'Additive',
2: 'Alkali',
3: 'Alkali',
4: 'Alkali',
5: 'Alkali',
6: 'Alkali',
7: 'Additive',
8: 'Additive',
9: 'Alkali',
10: 'Alkali',
11: 'Alkali',
12: 'Alkali',
13: 'Alkali'},
'Substance': {0: 'Irgafos 168',
1: 'Alkylphenylphosphate',
2: 'Calcium',
3: 'Kalium',
4: 'Lithium',
5: 'Magnesium',
6: 'Natrium',
7: 'Irgafos 168',
8: 'Alkylphenylphosphate',
9: 'Calcium',
10: 'Kalium',
11: 'Lithium',
12: 'Magnesium',
13: 'Natrium'},
'Value': {0: 0,
1: 0,
2: 2,
3: 2,
4: 1,
5: 2,
6: 3,
7: 2,
8: 3,
9: 2,
10: 3,
11: 1,
12: 2,
13: 3}}这张表看起来像这个样本表
{kind=link}
我使用下面的代码来获得一个嵌套的json,它是从这个回答中获取的。
j = (df.groupby(['Sample','Substance category'])
.apply(lambda x: x[['Substance','Value']].to_dict('records'))
.reset_index()
.rename(columns={0:'Substance'})
.to_json(orient='records'))我得到了下面的json。
[
{
"Sample": "1A",
"Substance": [
{
"Substance": "Irgafos 168",
"Value": 0
},
{
"Substance": "Alkylphenylphosphate",
"Value": 0
}
],
"Substance category": "Additive"
},
{
"Sample": "1A",
"Substance": [
{
"Substance": "Calcium",
"Value": 2
},
{
"Substance": "Kalium",
"Value": 2
},
{
"Substance": "Lithium",
"Value": 1
},
{
"Substance": "Magnesium",
"Value": 2
},
{
"Substance": "Natrium",
"Value": 3
}
],
"Substance category": "Alkali"
},
{
"Sample": "2A",
"Substance": [
{
"Substance": "Irgafos 168",
"Value": 2
},
{
"Substance": "Alkylphenylphosphate",
"Value": 3
}
],
"Substance category": "Additive"
},
{
"Sample": "2A",
"Substance": [
{
"Substance": "Calcium",
"Value": 2
},
{
"Substance": "Kalium",
"Value": 3
},
{
"Substance": "Lithium",
"Value": 1
},
{
"Substance": "Magnesium",
"Value": 2
},
{
"Substance": "Natrium",
"Value": 3
}
],
"Substance category": "Alkali"
}
]然而,我真正想要的是为“物质类别”定义一个加法级别。尽管我做了很多努力,但我还是想不出答案,没有一个答案能帮到我。
先谢谢你。
回答 2
Stack Overflow用户
回答已采纳
发布于 2022-07-05 13:37:04
那么,创建一个多级df并不是问题。但是当我将它导出到json时,它没有维护索引的嵌套结构。总之,我终于找到了答案。这只是用正确的关键字链接在google上搜索的问题。
Stack Overflow用户
发布于 2022-07-01 15:40:05
这将是我的过程:
- 将该数据集转换为数据格式。
- 可以用
to_json()完成从dataframe到json的写作
代码看起来如下:
#%%
import pandas as pd
d = {'Sample': {0: '1A',
1: '1A',
2: '1A',
3: '1A',
4: '1A',
5: '1A',
6: '1A',
7: '2A',
8: '2A',
9: '2A',
10: '2A',
11: '2A',
12: '2A',
13: '2A'},
'Substance category': {0: 'Additive',
1: 'Additive',
2: 'Alkali',
3: 'Alkali',
4: 'Alkali',
5: 'Alkali',
6: 'Alkali',
7: 'Additive',
8: 'Additive',
9: 'Alkali',
10: 'Alkali',
11: 'Alkali',
12: 'Alkali',
13: 'Alkali'},
'Substance': {0: 'Irgafos 168',
1: 'Alkylphenylphosphate',
2: 'Calcium',
3: 'Kalium',
4: 'Lithium',
5: 'Magnesium',
6: 'Natrium',
7: 'Irgafos 168',
8: 'Alkylphenylphosphate',
9: 'Calcium',
10: 'Kalium',
11: 'Lithium',
12: 'Magnesium',
13: 'Natrium'},
'Value': {0: 0,
1: 0,
2: 2,
3: 2,
4: 1,
5: 2,
6: 3,
7: 2,
8: 3,
9: 2,
10: 3,
11: 1,
12: 2,
13: 3}}
# make dataframe
df = pd.DataFrame(d)
# %% send to excel
json_path = "C:\\test\\test.json"
df.to_json(json_path)dataframe (在json之前)如下所示:
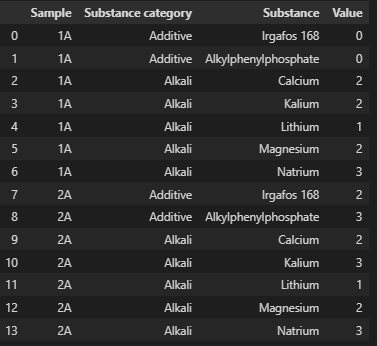
您可以根据您的意愿从这里操作数据。
您是在要求创建一个多级数据帧吗?如果是这样,那么最后一部分将在这里回答:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72830481
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号