
加权训练,测试,验证分割用于图像分类
加权训练,测试,验证分割用于图像分类
提问于 2022-07-01 06:51:42
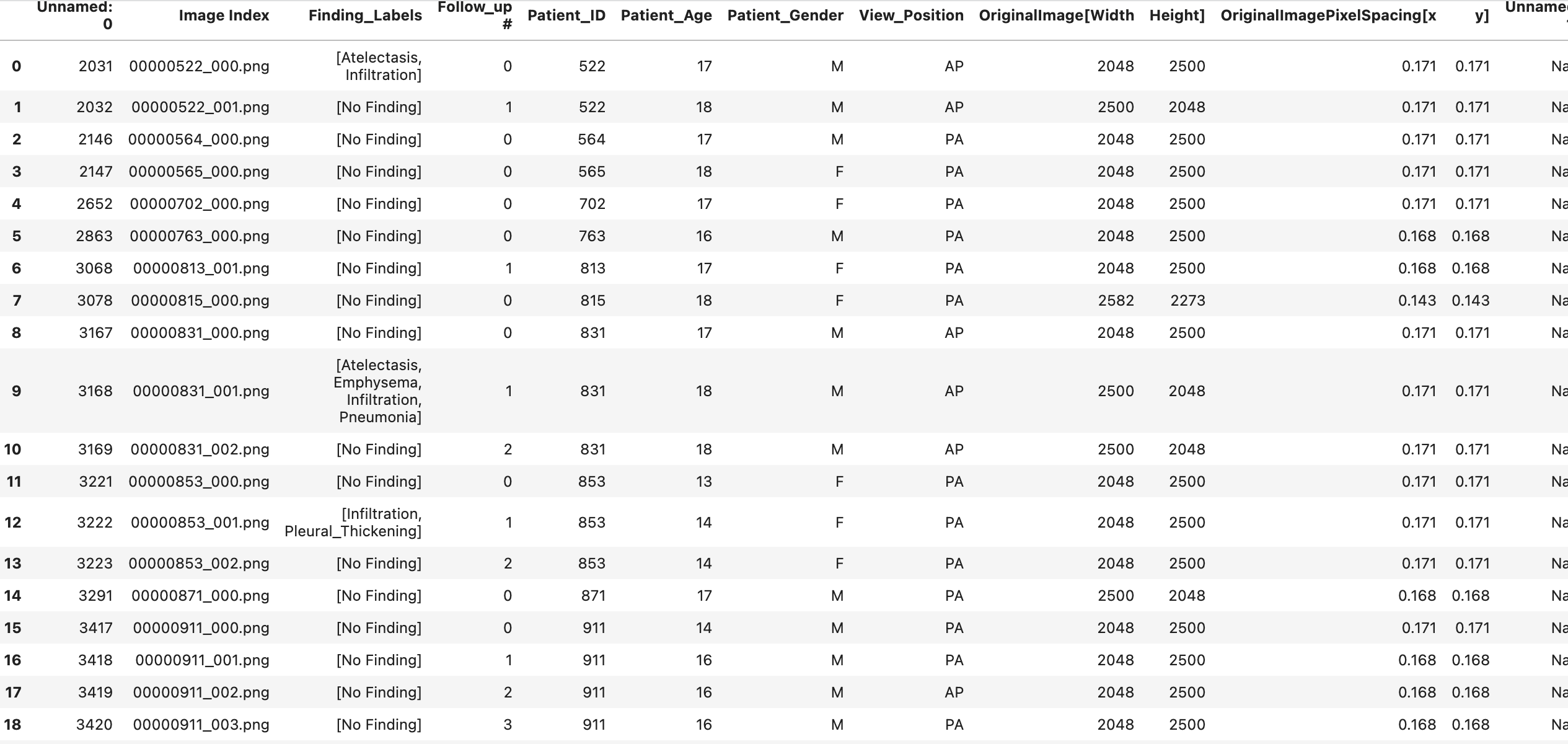
我试图将上面的数据分解成列车(80%)、验证(10%)和测试(10%);但是,我希望在每组中保持几乎相等的疾病数量。Finding_Labels列有链接到的疾病列表。
每个图像可能与多个疾病相关联,如第一行所见--这是一个小问题。因此,如果这3组疾病的数量几乎相等,我如何将其分开呢?
如果能在PyTorch上给出答案,我将不胜感激。
疾病名称和计数:
{'Atelectasis': 391,
'Infiltration': 1181,
'No Finding': 3479,
'Emphysema': 116,
'Pneumonia': 116,
'Pleural_Thickening': 130,
'Pneumothorax': 361,
'Mass': 241,
'Nodule': 190,
'Consolidation': 299,
'Edema': 124,
'Cardiomegaly': 157,
'Effusion': 506,
'Fibrosis': 25,
'Hernia': 1}回答 1
Stack Overflow用户
发布于 2022-07-01 07:30:06
正如评论中提到的,我将使用sklearn来解决您的问题。
例如,假设您有以下特性和标签数据集,其中一个属性的数量(y==1).sum()等于零属性(y==0).sum()的数量(因此您有一个对零的1.0比率):
from sklearn import datasets
X, y = datasets.make_blobs(n_samples=10000, centers=2, random_state=0)
print(np.bincount(y)[0]/np.bincount(y)[1]) # 1.0然后,您可以将数据分成培训、验证和测试数据,同时保持相同的属性比率,如下所示:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42, test_size=0.2)
X_val, X_test, y_val, y_test = train_test_split(X_test, y_test, stratify=y_test, random_state=42, test_size=0.5)
print(np.bincount(y_train)[0]/np.bincount(y_train)[1]) # 1.0
print(np.bincount(y_test)[0]/np.bincount(y_test)[1]) # 1.0
print(np.bincount(y_val)[0]/np.bincount(y_val)[1]) # 1.0
print(len(y_train), len(y_val), len(y_test)) # 8000, 1000, 1000页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72825372
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号