
StableBaselines3神经网络-为什么当我第二次调用model.learn()时性能下降/不稳定?
我使用StableBaselines3 (基于PyTorch)来训练一个神经网络来完成强化学习任务。
我正在使用Tensorboard记录平均插曲奖励,以跟踪培训进度。然而,我注意到了一些对我来说毫无意义的事情。
下面是一些培训的截图:
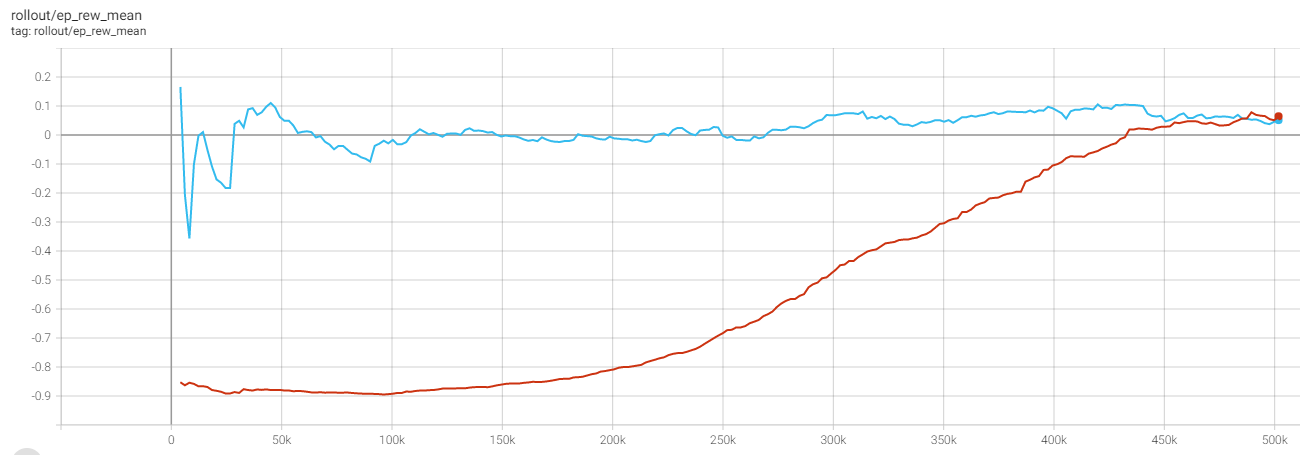
红线是在通过model=PPO(.)创建我的模型之后,调用model.learn(500000)时的平均插曲奖励。蓝线是当第一次model.learn(500000)训练结束后,我再次打电话给model.learn(500000)时的平均插曲奖励,我以为这只会继续以前的model.learn()停止的训练。
为什么第二次model.learn()运行的初始性能会有如此大的下降(以及不稳定性)?
回答 1
Stack Overflow用户
发布于 2022-07-12 07:15:36
如果没有更多关于模型和优化器的哪些部分被保存和恢复的信息,就不可能知道是什么导致了这种行为。
最有可能的解释是,只存储了演员-评论家的权重,而与勘探无关的权重。在使用PPO对策略进行训练时,通常会在参与者网络的输出中加入动作噪声,以达到探索的目的。高斯或均匀噪声是一种非常普遍的选择。图中的噪声参数在第二次运行时使用相对较高的默认值初始化。然后,优化器迅速将这些值降到较低的值,此时策略又开始变得更加确定,从而获得相对恒定的平均插曲奖励。
为了调试这些问题,您需要绘制动作噪声的大小。在这种情况下,它很可能在第二次运行时以较高的值开始,并在第二次运行的迭代~150 k时达到(大约)它在第一次运行结束时的值。
https://stackoverflow.com/questions/72792759
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号