
从改进线性回归中提取特征的重要性
从改进线性回归中提取特征的重要性
提问于 2022-06-26 10:22:33
我有以下代码:
modelClf = AdaBoostRegressor(base_estimator=LinearRegression(), learning_rate=2, n_estimators=427, random_state=42)
modelClf.fit(X_train, y_train)当我试图解释和改进结果时,我想看到特性的重要性,但是我发现一个错误,就是线性回归并不能真正做到这一点。
好的,听起来很合理,所以我试着使用.coef_,因为它应该适用于线性回归,但它在适当的地方,结果与adaboost回归不兼容。
是否有任何方法可以找到特征的重要性,或者当它被用于线性回归时是不可能的?
回答 2
Stack Overflow用户
发布于 2022-06-30 13:50:35
Issue12137建议使用coefs_添加对此的支持,尽管需要选择如何对负系数进行规范化。还有关于何时系数是非常重要的代表的问题是 (您至少应该首先缩放您的数据)。然后是关于什么时候自适应助推有助于线性模型的问题是。
快速完成此操作的一种方法是修改LinearRegression类:
class MyLinReg(LinearRegression):
@property
def feature_importances_(self):
return self.coef_ # assuming one output
modelClf = AdaBoostRegressor(base_estimator=MyLinReg(), ...)Stack Overflow用户
发布于 2022-06-30 12:48:22
使用下面的代码检查,有一个特性重要性的属性:
import pandas as pd
import random
from sklearn.ensemble import AdaBoostRegressor
df = pd.DataFrame({'x1':random.choices(range(0, 100), k=10), 'x2':random.choices(range(0, 100), k=10)})
df['y'] = df['x2'] * .5
X = df[['x1','x2']].values
y = df['y'].values
regr = AdaBoostRegressor(random_state=0, n_estimators=100)
regr.fit(X, y)
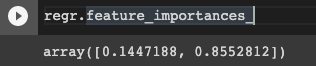
regr.feature_importances_
输出:您可以看到功能2更重要,因为Y只是其中的一半(因为数据是以这种方式创建的)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72760721
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号