
更快的Python Lemmatization
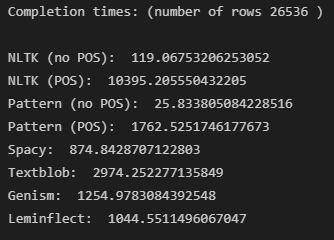
我一直在测试不同的柠檬化方法,因为它将用于一个非常大的语料库。下面是我的方法和结果。有谁有任何技巧来加速这些方法吗?空间是最快的,包括部分语音标记(首选),其次是柠檬。我是不是走错路了?这些函数被应用于包含文本的数据模型上的熊猫.apply()。
def prepareString_nltk_current(x):
lemmatizer = WordNetLemmatizer()
x = re.sub(r"[^0-9a-z]", " ", x)
if len(x)==0:
return ''
tokens = word_tokenize(x)
tokens = [lemmatizer.lemmatize(word).strip() for word in tokens if word not in stop_words]
if len(tokens)==0:
return ''
return ' '.join(map(str,tokens))
def prepareString_pattern(x):
error = 'Error'
x = re.sub(r"[^0-9a-z.,;]", " ", x)
if len(x)==0:
return ''
try:
return " ".join([lemma(wd) if wd not in ['this', 'his'] else wd for wd in x.split()])
except StopIteration:
return error
def prepareString_pattern(x):
error = 'Error'
x = re.sub(r"[^0-9a-z.,;]", " ", x)
if len(x)==0:
return ''
try:
return " ".join([lemma(wd) if wd not in ['this', 'his'] else wd for wd in x.split()])
except StopIteration:
return error
def prepareString_spacy_pretrained(x):
if len(x)==0:
return ''
doc = nlp(x)
return re.sub(r"[^0-9a-zA-Z]", " ", " ".join(str(token.lemma) for token in doc)).lower()
def get_wordnet_pos(word):
lemmatizer = WordNetLemmatizer()
"""Map POS tag to first character lemmatize() accepts"""
tag = nltk.pos_tag([word])[0][1][0].upper()
tag_dict = {"J": 'a',
"N": 'n',
"V": 'v',
"R": 'r'}
return lemmatizer.lemmatize(word, tag_dict.get(tag, 'n'))
def prepareString_nltk_pos(x):
tokens = word_tokenize(x)
if len(x)==0:
return ''
return " ".join(get_wordnet_pos(w) for w in tokens)
def prepareString_textblob(x):
sent = TextBlob(x)
tag_dict = {"J": 'a',
"N": 'n',
"V": 'v',
"R": 'r'}
words_and_tags = [(w, tag_dict.get(pos[0], 'n')) for w, pos in sent.tags]
return " ".join([wd.lemmatize(tag) for wd, tag in words_and_tags])
def prepareString_genism(x):
return " ".join([wd.decode('utf-8').split('/')[0] for wd in lemmatize(x)])
def prepareString_leminflect(x):
doc = nlp(x)
return " ".join([str(x._.lemma) for x in doc])
def prepareString_pattern_pos(x):
s = parsetree(x, tags=True, lemmata=True)
for sentence in s:
return re.sub(r"[^0-9a-zA-Z]", " ", " ".join([str(x._.lemma()) for x in doc])).lower()
回答 1
Stack Overflow用户
发布于 2022-06-21 14:26:13
我认为是Spacy解析(创建POS标签等)花费了时间,而不是实际的柠檬化。从Lemminflect的REAME中,该库平均每个引理占用42‘s(不包括解析)。看上去你的花费更像是42 It。1044 s/ 26536引理)。这意味着你真的需要加快Spacy的解析速度。
- 你可以使用最小的Spacy模型,如果你还没有。加载(“en_core_web_sm”)
- 我认为您可以禁用NER和依赖项解析来加快速度,因为您不需要这些信息。有关如何加载"nlp“和禁用这些文件,请参见Spacy的文档(我不确定这是否可以完成,但我怀疑它可以)。
- 您可以多线程您的代码,这将使您的速度几乎线性与您的机器的核心数目。
您还可以使用调用getLemmas()和param lemmatize_oov=False来稍微加快Lemminflect的速度。这将只做字典引理查找,这是非常快的。这不会引起失语症。错了,罕见的词,)这要慢得多。请注意,您必须解析这些句子才能获得upos。在西班牙,我认为这是token.pos_。有关lemminflect所期望的内容,请参见词类标签,以及Spacy的文档来验证这是否是.pos_属性。
然而,我认为您的大问题是解析和柠檬化速度的小变化不会对您产生太大的影响。
我还应该指出,只有在句子中有单词时,解析才能起作用。从您的代码看,它看起来是正确的,但我不能确定。如果您只给了一个单词或一小块文本,请确保您是这样做的,因为解析器不能选择正确的POS。
https://stackoverflow.com/questions/72701185
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号