
在Pandas中指定多索引头时使用usecols
在Pandas中指定多索引头时使用usecols
提问于 2022-06-20 05:51:17
我有一个庞大的数据可以读取基于两个标题,但当我使用多索引方法,我无法使用'usecols‘在熊猫数据。
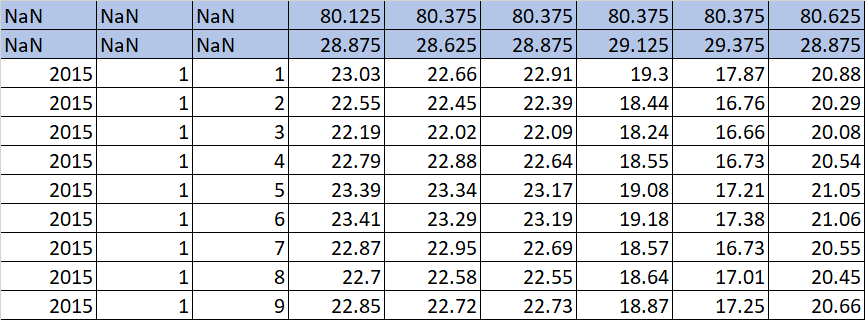
当我用
df = pd.read_csv(files, delimiter=' ', header=[0,1])这需要太多的时间和记忆。
我尝试使用的另一种方法是
df = pd.read_csv(files, delimiter=' ', usecols = ["80.375"])它只取一个colomn,而应该取头为80.375的所有四个colomn。
期望输出
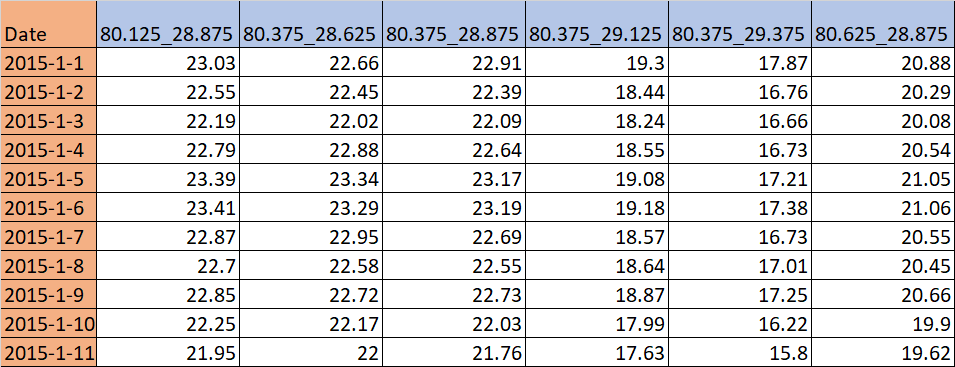
请提出其他方法。
提前感谢
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-06-20 06:47:58
您可以使用两次传递来提取数据和标头。
# read_csv common options
opts = {'sep': ' ', 'header': None}
# Extract headers, create MultiIndex
headers = pd.read_csv('data.csv', **opts, nrows=2)
mi = pd.MultiIndex.from_frame(headers.T)
# Keep desired columns
dti = [0, 1, 2] # Year, Month, Day
cols = mi.get_locs([80.375]).tolist()
# Build dataframe
df = pd.read_csv('data.csv', **opts, skiprows=2, index_col=dti, usecols=dti+cols)
df.columns = mi[cols]
df = df.rename_axis(index=['Year', 'Month', 'Day'], columns=['Lvl1', 'Lvl2'])
df.index = pd.to_datetime(df.index.to_frame()).rename('DateTime')输出:
>>> df
Lvl1 80.375
Lvl2 28.625 28.875 29.125 29.375
DateTime
2015-01-01 21 22 23 24
2015-01-02 31 32 33 34
2015-01-03 41 42 43 44
2015-01-04 51 52 53 54输入csv文件:
80.125 80.375 80.375 80.375 80.375 80.625
28.875 28.625 28.875 29.125 29.375 28.875
2015 1 1 20 21 22 23 24 25
2015 1 2 30 31 32 33 34 35
2015 1 3 40 41 42 43 44 45
2015 1 4 50 51 52 53 54 55更新
--我需要在单个标题行中转换输出。
# Extract headers, create MultiIndex
headers = pd.read_csv('data.csv', sep=' ', header=None, nrows=2)
mi = pd.MultiIndex.from_frame(headers.T)
# Keep desired columns
dti_cols = [0, 1, 2] # Year, Month, Day
dti_names = ['Year', 'Month', 'Day']
dat_cols = mi.get_locs([80.375]).tolist()
dat_names = mi[cols].to_flat_index().map(lambda x: f"{x[0]}_{x[1]}").tolist()
# Build dataframe
df = (pd.read_csv('data.csv', sep=' ', header=None, skiprows=2,
usecols=dti_cols+dat_cols, names=dti_names+dat_names,
parse_dates={'Date': ['Year', 'Month', 'Day']}))输出:
>>> df
Date 80.375_28.625 80.375_28.875 80.375_29.125 80.375_29.375
0 2015-01-01 21 22 23 24
1 2015-01-02 31 32 33 34
2 2015-01-03 41 42 43 44
3 2015-01-04 51 52 53 54页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72682729
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号