
使用k均值预测标签查看PCA散点图是否正确?
使用k均值预测标签查看PCA散点图是否正确?
提问于 2022-06-16 19:17:36
对于此处提供的数据:
feat_1 feat_2 Label
4.818919448 -8.88997718 0
2.239877125 -7.142062835 0
2.715454379 -9.392740116 0
1.457970779 -9.295304121 0
3.396769719 -4.696564243 0
-0.251264375 -3.11639814 0
1.553138885 -2.56360423 0
2.556077961 -1.639727669 0
3.264100784 -5.353501855 0
5.54079929 -2.810777111 0
-2.063969924 0.127805678 1
-1.691797179 0.835738844 1
-1.350084344 0.469993022 1
-1.672611658 0.873301506 1
-1.956488821 0.804911876 1
-1.529121941 1.112561558 1
-2.091905556 0.72908025 1
-1.835806179 0.801126086 1
-1.963433251 0.558394092 1
-2.576833733 -0.148751731 1
5.262121279 -0.291153029 2
4.150999653 4.60229228 2
2.538967939 5.642889255 2
9.908816157 2.380103599 2
9.876931469 2.29522071 2
6.691577612 -2.214740473 2
11.75361142 9.650193692 2
4.099660592 5.048216039 2
8.49165607 2.47194124 2
8.243607045 2.831411268 2其中X作为特性(表的前2列),标签y由第三列提供。
我使用PCA,然后进行k-均值聚类。
码
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.decomposition import PCA
X = df.drop(columns=['Label']).values
y = df['Label'].values
pca = PCA().fit(X)
x_pca = pca.fit_transform(X)
from sklearn.cluster import KMeans
k_means = KMeans(n_clusters=3, random_state=42)
k_means = k_means.fit(x_pca)
kmeans_labels = k_means.predict(x_pca)
kmeans_labels
target_names = ['class_0', 'class_1', 'class_2']
plt.figure(figsize=(8,6))
plot = plt.scatter(x_pca[:,0],x_pca[:,1],c=y,s=20, cmap=plt.cm.jet, linewidths=0, alpha=0.5)
plt.scatter(k_means.cluster_centers_[:,0], k_means.cluster_centers_[:,1], marker="x", color='k', s=40)
plt.legend(handles=plot.legend_elements()[0], labels=list(target_names))
plt.xlabel('feat_1')
plt.ylabel('feat_2')
plt.title('KMeans')
plt.show()如果我在c=y绘图中使用了plt.scatter,就会得到以下内容:
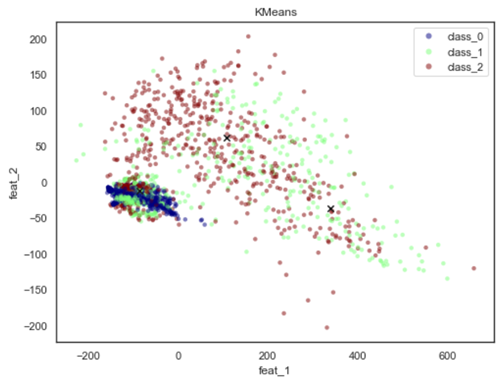
如果我在c=kmeans_labels绘图中使用了plt.scatter,那么我会得到以下内容:
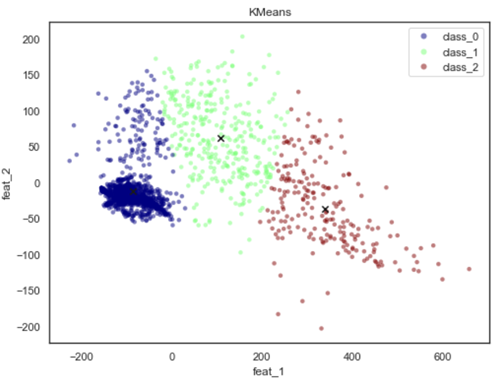
第二幅图很好地分离了这些类。
这是正确的观点吗?
此外,这种数据分离是否可以用于训练这样的模型:
X_train, X_test, y_train, y_test = train_test_split(x_pca, kmeans_labels, test_size=0.3, random_state=42)还是我必须像这样坚持原来的标签:
X_train, X_test, y_train, y_test = train_test_split(x_pca, y, test_size=0.3, random_state=42)地点:y = df['Label'].values
谢谢你的帮助和时间!
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-06-23 11:43:31
当您使用kmeans的标签进行可视化时,您将显示数据是如何聚集在一起的,而忽略了原始标签。但是你的数据已经被标记了,所以聚类没有意义。因此,第一个可视化是正确的,同样,您应该只使用原始标签来训练任何模型。
根据第一次可视化,您的类似乎相互交织在一起,简单的模型很可能无法预测。如果可能的话,在使用模型之前,我会推荐更多的特性工程。如果没有任何额外的建议,我们将需要更多关于您的数据的信息。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72650877
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号