
大型数据存储中的文件保留机制
最近,我在mp4文件保留方面遇到了性能问题。我有一种录音机,可以从多个RTSP流中保存1分钟长的mp4文件。这些文件存储在文件树中的外部驱动器上,如下所示:
./recordings/{camera_name}/{YYYY-MM-DD}/{HH-MM}.mp4除了视频文件,这个驱动器上还有许多其他文件是不考虑的(除非它们有mp4扩展名),因为它们占用的空间要小得多。
文件保留的假设如下。每分钟,负责录制的python脚本,检查外部驱动器实现级别。如果级别高于80%,则执行整个驱动器的扫描,并查找.mp4文件。扫描完成后,它会根据其创建日期对文件列表进行排序,并删除与摄像机编号相等的最老文件的数量。
代码中负责文件保留的部分如下所示。
total, used, free = shutil.disk_usage("/home")
used_percent = int(used / total * 100)
if used_percent > 80:
logging.info("SSD usage %s. Looking for the oldest files", used_percent)
try:
oldest_files = sorted(
(
os.path.join(dirname, filename)
for dirname, dirnames, filenames in os.walk('/home')
for filename in filenames
if filename.endswith(".mp4")
),
key=lambda fn: os.stat(fn).st_mtime,
)[:len(camera_devices)]
logging.info("Removing %s", oldest_files)
for oldest_file in oldest_files:
os.remove(oldest_file)
logging.info("%s removed", oldest_file)
except ValueError as e:
# no files to delete
pass(/home是外部驱动器安装点)
问题是,当我使用256或512 GB的SSD时,这种机制曾经用作一个魅力。现在我需要更大的空间(更多的相机和更长的存储时间),在更大的SSD上创建文件列表需要很长时间(现在从2到5 TB,未来可能是8 TB )。扫描过程需要超过1分钟,可以通过更少地执行它和延长“删除”文件列表的长度来解决问题。真正的问题是,进程本身使用了大量的CPU负载(通过I/O操作)。整个系统的性能下降是可见的。其他应用程序,如一些简单的计算机视觉算法,工作速度较慢,CPU负载甚至会引起内核恐慌。
我工作的HW是Nvidia Jetson Nano和Xavier NX。正如我前面所描述的,这两种设备的性能都有问题。
问题是,如果您知道一些算法或开箱即用的软件来保存文件,这将适用于我所描述的情况。或者有一种方法可以重写我的代码,让它更可靠并执行?
编辑:
我能够通过限制空间来降低os.walk()对check.Now的影响,我只扫描/home/recordings和/home/recognition/,这两个目录树也较低(用于递归扫描)。同时,我还添加了.jpg文件检查,所以现在我从.mp4和.jpg两方面进行查看。在这种实现中,结果要好得多。
然而,我需要进一步的优化。我准备了一些测试用例,并在1个TB驱动器上测试,这个驱动器的填充率为80% (主要是媒体文件)。我附上了下面每个案例的分析结果。
@time_measure
def method6():
paths = [
"/home/recordings",
"/home/recognition",
"/home/recognition/marked_frames",
]
files = []
for path in paths:
files.extend((
os.path.join(dirname, filename)
for dirname, dirnames, filenames in os.walk(path)
for filename in filenames
if (filename.endswith(".mp4") or filename.endswith(".jpg")) and not os.path.islink(os.path.join(dirname, filename))
))
oldest_files = sorted(
files,
key=lambda fn: os.stat(fn).st_mtime,
)
print(oldest_files[:5])

@time_measure
def method7():
ext = [".mp4", ".jpg"]
paths = [
"/home/recordings/*/*/*",
"/home/recognition/*",
"/home/recognition/marked_frames/*",
]
files = []
for path in paths:
files.extend((file for file in glob(path) if not os.path.islink(file) and (file.endswith(".mp4") or file.endswith(".jpg"))))
oldest_files = sorted(files, key=lambda fn: os.stat(fn).st_mtime)
print(oldest_files[:5])
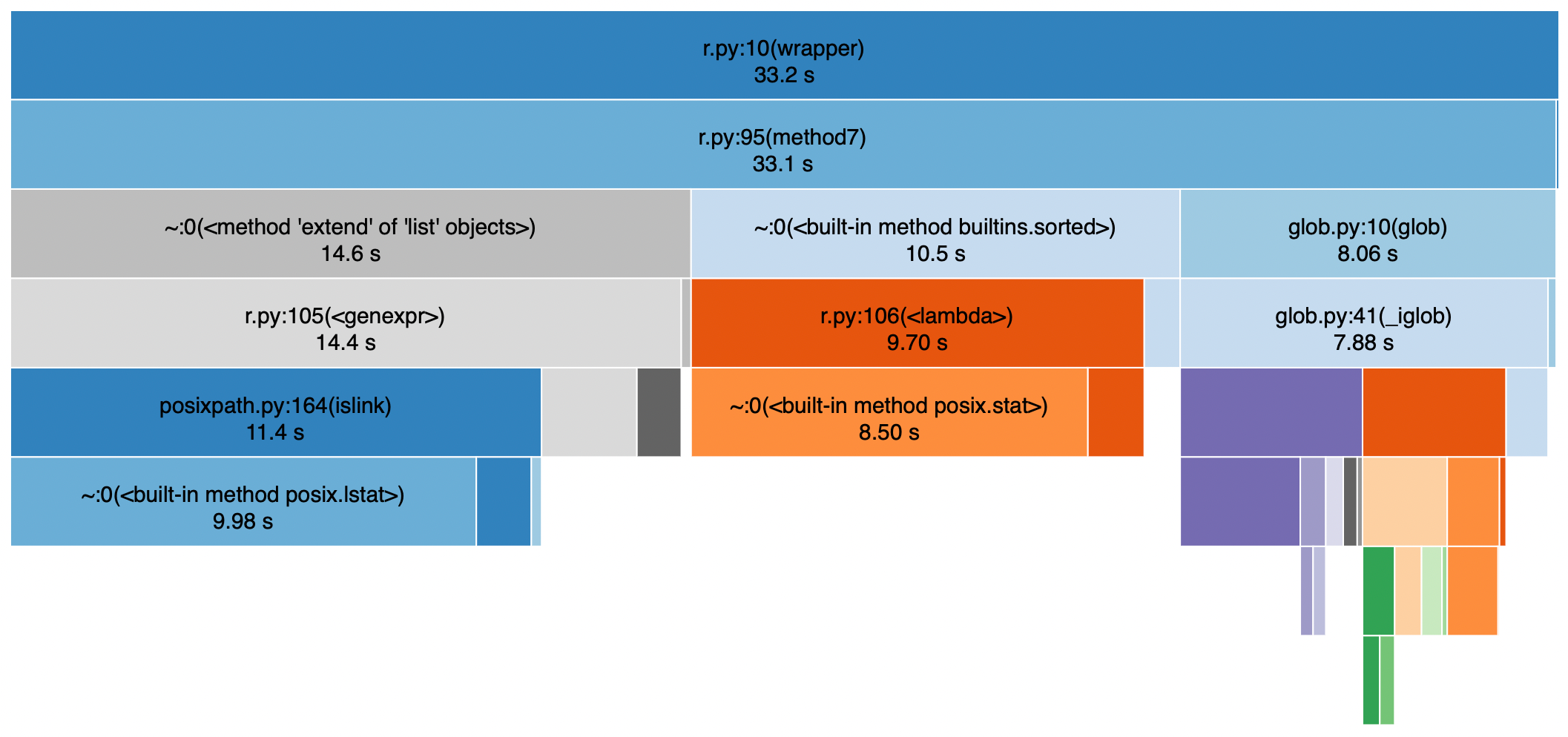
上次~100秒相同数据集上的原始实现
EDIT2
@norok2 2提案比较
我从上面将它们与method6和method7进行了比较。我试了几次,结果也差不多。
Testing method7
['/home/recordings/35e68df5-44b1-5010-8d12-74b892c60136/2022-06-24/17-36-18.jpg', '/home/recordings/db33186d-3607-5055-85dd-7e5e3c46faba/2021-11-22/11-27-30.jpg', '/home/recordings/acce21a2-763d-56fe-980d-a85af1744b7a/2021-11-22/11-27-30.jpg', '/home/recordings/b97eb889-e050-5c82-8034-f52ae2d99c37/2021-11-22/11-28-23.jpg', '/home/recordings/01ae845c-b743-5b64-86f6-7f1db79b73ae/2021-11-22/11-28-23.jpg']
Took 24.73726773262024 s
_________________________
Testing find_oldest
['/home/recordings/35e68df5-44b1-5010-8d12-74b892c60136/2022-06-24/17-36-18.jpg', '/home/recordings/db33186d-3607-5055-85dd-7e5e3c46faba/2021-11-22/11-27-30.jpg', '/home/recordings/acce21a2-763d-56fe-980d-a85af1744b7a/2021-11-22/11-27-30.jpg', '/home/recordings/b97eb889-e050-5c82-8034-f52ae2d99c37/2021-11-22/11-28-23.jpg', '/home/recordings/01ae845c-b743-5b64-86f6-7f1db79b73ae/2021-11-22/11-28-23.jpg']
Took 34.355509757995605 s
_________________________
Testing find_oldest_cython
['/home/recordings/35e68df5-44b1-5010-8d12-74b892c60136/2022-06-24/17-36-18.jpg', '/home/recordings/db33186d-3607-5055-85dd-7e5e3c46faba/2021-11-22/11-27-30.jpg', '/home/recordings/acce21a2-763d-56fe-980d-a85af1744b7a/2021-11-22/11-27-30.jpg', '/home/recordings/b97eb889-e050-5c82-8034-f52ae2d99c37/2021-11-22/11-28-23.jpg', '/home/recordings/01ae845c-b743-5b64-86f6-7f1db79b73ae/2021-11-22/11-28-23.jpg']
Took 25.81963086128235 smethod7 (glob())
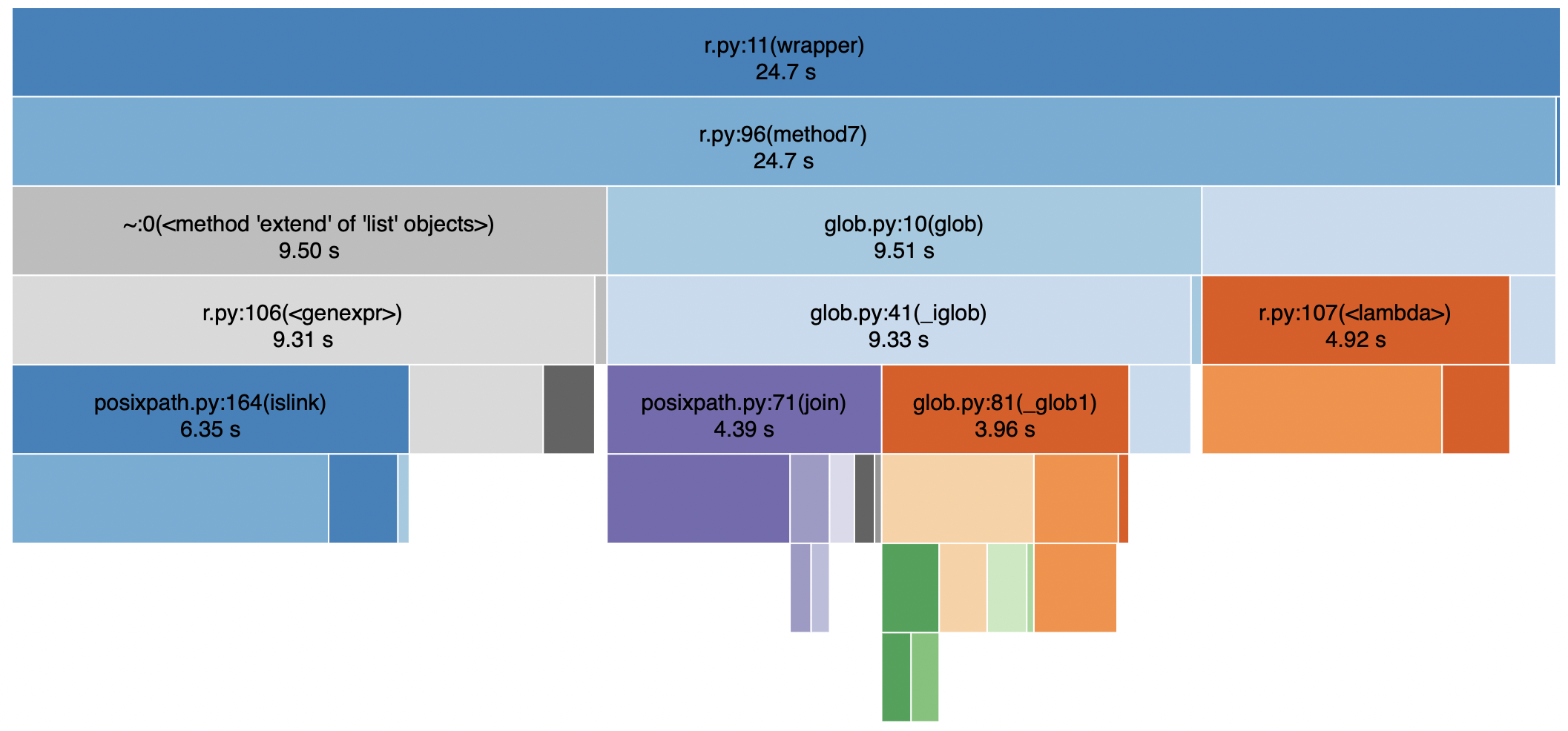
iglob()
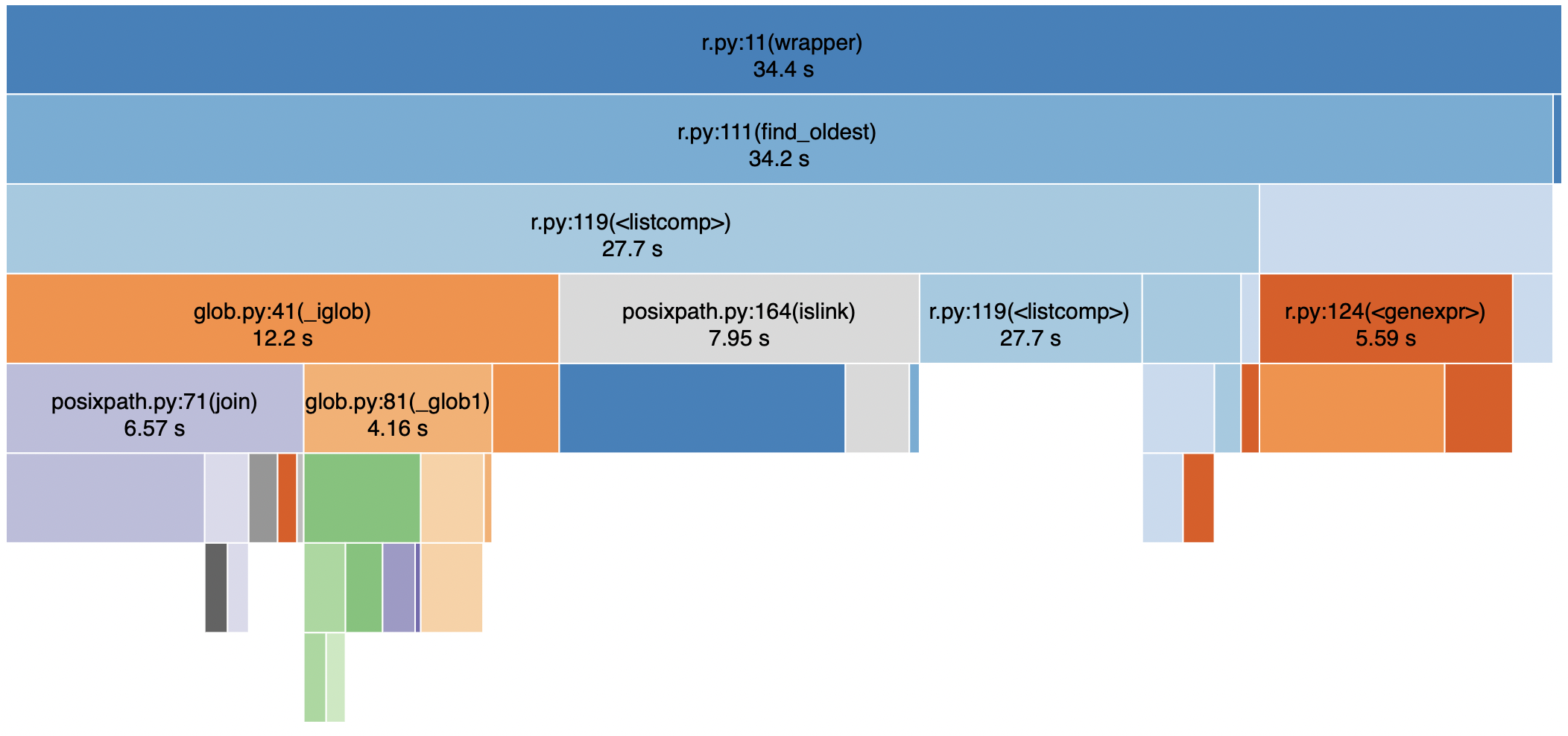
Cython
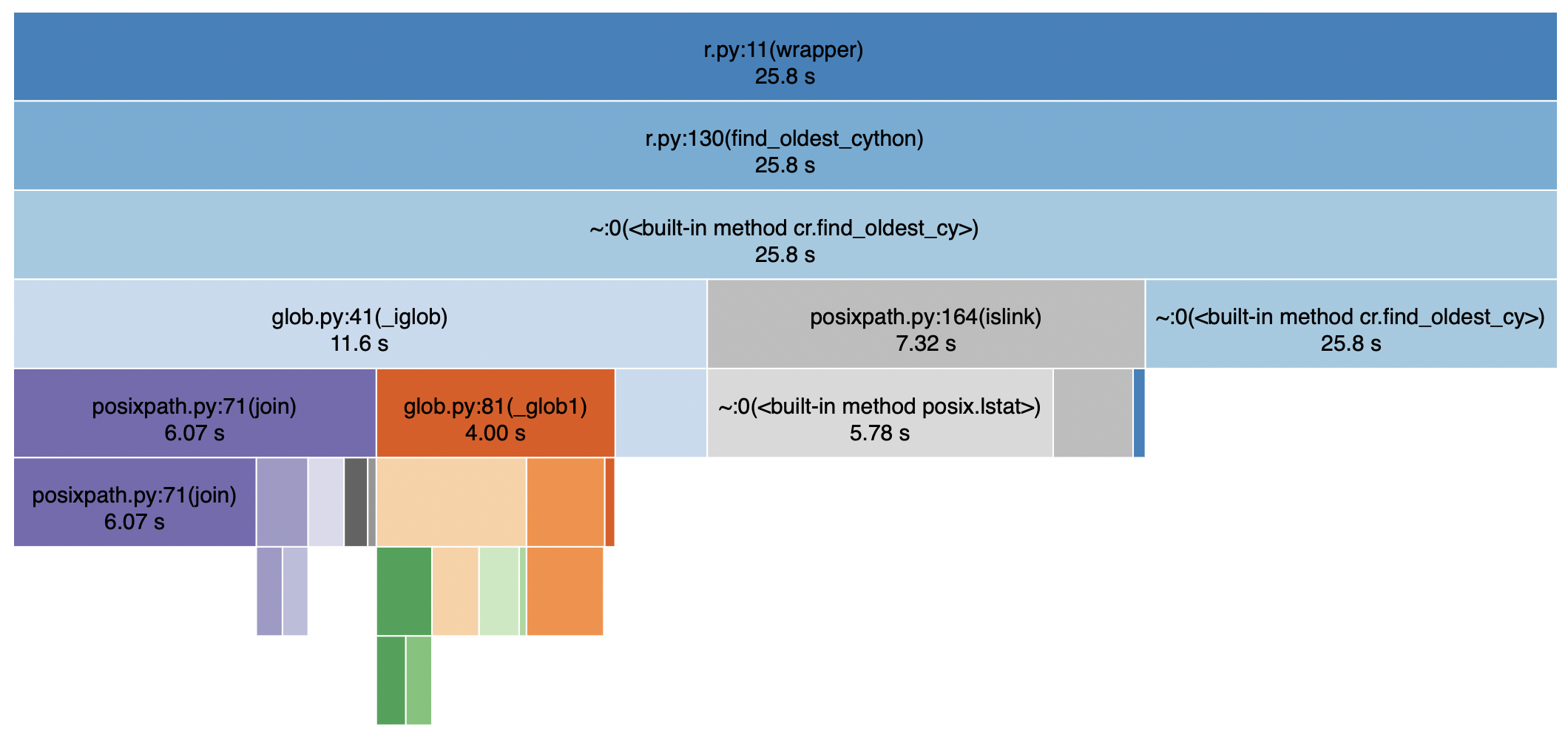
回答 3
Stack Overflow用户
发布于 2022-06-25 15:14:20
在您的method7()之上,您可以通过以下方式获得额外的几个百分点的速度:
import os
import glob
def find_oldest(paths=("*",), exts=(".mp4", ".jpg"), k=5):
result = [
filename
for path in paths
for filename in glob.iglob(path)
if any(filename.endswith(ext) for ext in exts) and not os.path.islink(filename)]
mtime_idxs = sorted(
(os.stat(fn).st_mtime, i)
for i, fn in enumerate(result))
return [result[mtime_idxs[i][1]] for i in range(k)]主要改进是:
machines
- str.endswith()
- 使用iglob而不是glob --虽然它的速度与glob相当,但在执行低端之前,它所需的内存要少得多,这样才能完成据称更昂贵的os.path.islink(),这有助于减少由于shortcircuiting
- an中间列表而产生的此类调用的次数,从而将os.stat()调用
降到最低。
使用Cython还可以进一步加快速度:
%%cython --cplus -c-O3 -c-march=native -a
import os
import glob
cpdef find_oldest_cy(paths=("*",), exts=(".mp4", ".jpg"), k=5):
result = []
for path in paths:
for filename in glob.iglob(path):
good_ext = False
for ext in exts:
if filename.endswith(ext):
good_ext = True
break
if good_ext and not os.path.islink(filename):
result.append(filename)
mtime_idxs = []
for i, fn in enumerate(result):
mtime_idxs.append((os.stat(fn).st_mtime, i))
mtime_idxs.sort()
return [result[mtime_idxs[i][1]] for i in range(k)]我对以下文件的测试:
def gen_files(n, exts=("mp4", "jpg", "txt"), filename="somefile", content="content"):
for i in range(n):
ext = exts[i % len(exts)]
with open(f"{filename}{i}.{ext}", "w") as f:
f.write(content)
gen_files(10_000)产生以下情况:
funcs = find_oldest_OP, find_oldest, find_oldest_cy
timings = []
base = funcs[0]()
for func in funcs:
res = func()
is_good = base == res
timed = %timeit -r 8 -n 4 -q -o func()
timing = timed.best * 1e3
timings.append(timing if is_good else None)
print(f"{func.__name__:>24} {is_good} {timing:10.3f} ms")
# find_oldest_OP True 81.074 ms
# find_oldest True 70.994 ms
# find_oldest_cy True 64.335 msfind_oldest_OP基于OP的method7(),如下所示:
def find_oldest_OP(paths=("*",), exts=(".mp4", ".jpg"), k=5):
files = []
for path in paths:
files.extend(
(file for file in glob.glob(path)
if not os.path.islink(file) and any(file.endswith(ext) for ext in exts)))
oldest_files = sorted(files, key=lambda fn: os.stat(fn).st_mtime)
return oldest_files[:k]Cython版本似乎表明执行时间减少了25%。
Stack Overflow用户
发布于 2022-06-24 09:09:07
您可以使用subprocess模块直接列出所有mp4文件,而不必遍历目录中的所有文件。
import subprocess as sb
oldest_files = sb.getoutput("dir /b /s .\home\*.mp4").split("\n")).sort(lambda fn: os.stat(fn).st_mtime,)[:len(camera_devices)]Stack Overflow用户
发布于 2022-06-24 19:39:38
一个快速的优化就是不要费心检查文件创建时间和信任文件名。
total, used, free = shutil.disk_usage("/home")
used_percent = int(used / total * 100)
if used_percent > 80:
logging.info("SSD usage %s. Looking for the oldest files", used_percent)
try:
files = []
for dirname, dirnames, filenames in os.walk('/home/recordings'):
for filename in filenames:
files.push((
name := os.path.join(dirname, filename),
datetime.strptime(
re.search(r'\d{4}-\d{2}-\d{2}\/\d{2}-\d{2}', name)[0],
"%Y-%m-%d/%H-%M"
))
oldest_files = files.sort(key=lambda e: e[1])[:len(camera_devices)]
logging.info("Removing %s", oldest_files)
for oldest_file in oldest_files:
os.remove(oldest_file)
# logging.info("%s removed", oldest_file)
logging.info("Removed")
except ValueError as e:
# no files to delete
passhttps://stackoverflow.com/questions/72645232
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号