
人工智能多标签分类识别单个产品
我正在从事一个人工智能项目,用于识别PDF文档中的文本。我想给训练人工智能模型的例子贴上标签,但我站在十字路口,不知道该选择什么方法。这里有一些关于用例的背景知识。
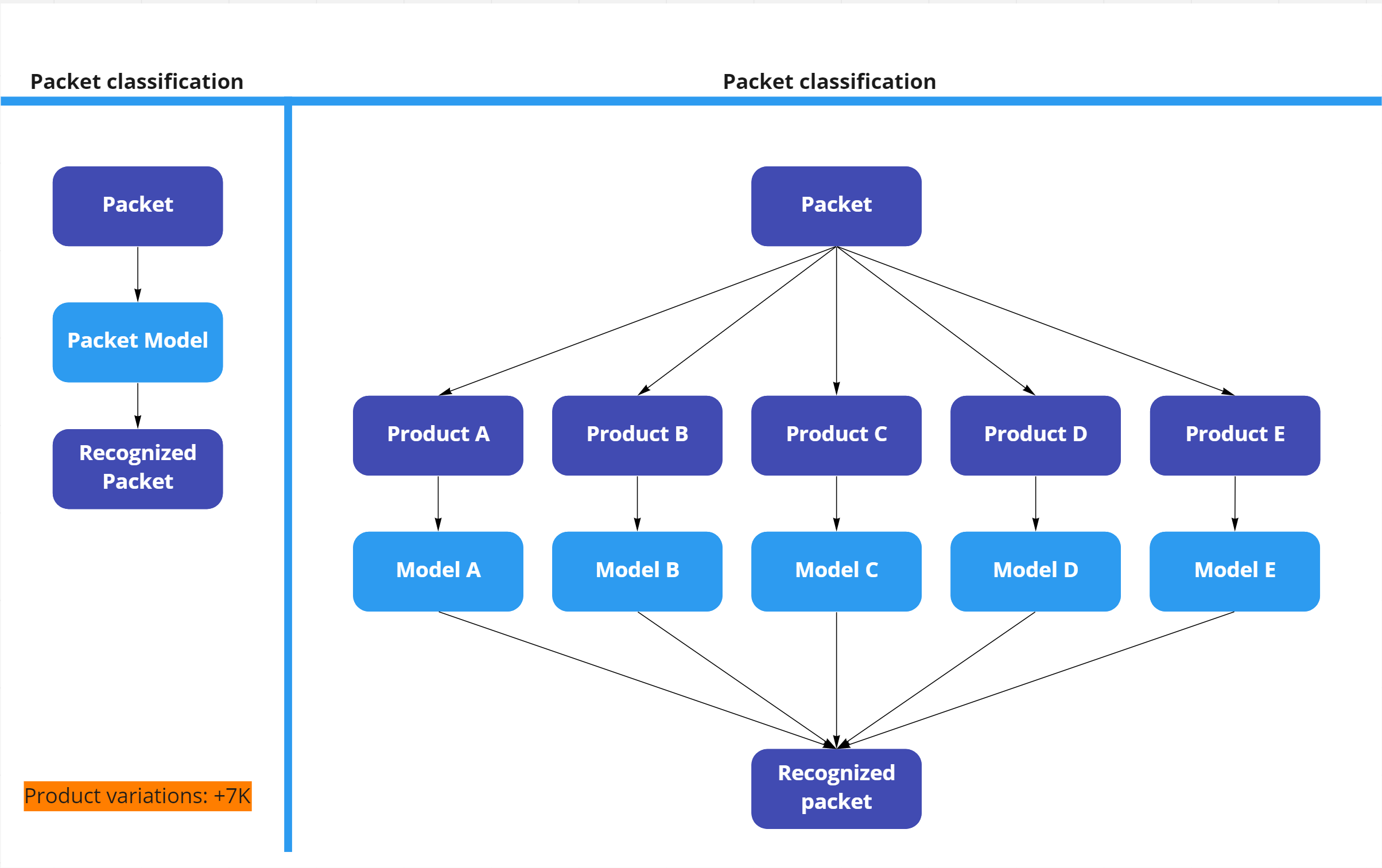
PDF文档存在于多个页面中,从现在起称为数据包。这些单独的页面表示包中存在的产品。这些产品的布局总是相同的,但是标签(如何和哪些数据保存在源系统中)可能有很大的不同。例如:产品的房子,汽车,马达,滑板车,和船可以存在于一个包。需要为每个产品保存的信息是不同的。比如,汽车、摩托车和滑板车的牌照号码,而房子的车牌号码是m2。
有350多种不同的产品。所以有太多的可能的组合。对于这个项目,我只想识别7种不同的产品。因此,更好的做法是将数据包标记为一个整体,并在此基础上对模型进行培训。还是先将包分割成单个产品,然后再将单个产品提供给相应的模型。
- 不要把包分成单独的产品。列车模型作为一个整体。
- B=将包装分成单独的产品。每个产品都会得到它的个别型号。
有一幅图片可以帮助澄清上面的文字:
选项A或选项B可视化
回答 1
Stack Overflow用户
发布于 2022-08-09 04:18:23
我会以不同的方式处理这个问题。
我假设类似的产品页面有类似的解析方法,例如: cars在这个位置总是有注册年(不管是在某个关键字或(x,y)坐标之后)。
首先,为每个产品页编写相应的解析规则,以获取所需的信息。这里有从pdf中解析文本的库,这是python示例。
然后,将数据包分割成单独的页面,并训练一个机器学习模型,使其能够对“它是什么产品”进行分类。
完整的管道如下: 1.将包分成2页;2.将每个产品页分类为3类;3.应用相应的解析器4.组合回(这就是您想要的)
对于分类器,我会选择简单的作为关键字的决策树/随机森林,或者选择复杂的作为基于文本的神经网络。
https://stackoverflow.com/questions/72614294
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号