
TensorFlow回归与EarlyStopping和Dropout对拟合不良的影响
我对ML很陌生,我想知道我错过了什么或者做错了什么。
我试图弄清楚为什么我的数据在申请早停和辍学时不合适,但是当我不使用早停或辍学时,拟合似乎是可以的.
我正在使用的数据集:https://www.kaggle.com/datasets/kanths028/usa-housing
模型参数:数据集有5个特性可供训练,目标是我选择了4层任意周期600 (太多了)的价格,因为我想测试早期停止优化器和损失,因为与SKLearns LinearRegression (MAE约为81 K)相比,它们似乎获得了最一致的结果。
数据预处理:
X = df[df.columns[:-2]].values
y = df['Price'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=42)
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)合身看起来没问题:
model = Sequential()
model.add(Dense(5, activation='relu'))
model.add(Dense(5, activation='relu'))
model.add(Dense(5, activation='relu'))
model.add(Dense(5, activation='relu'))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mae')
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=600)
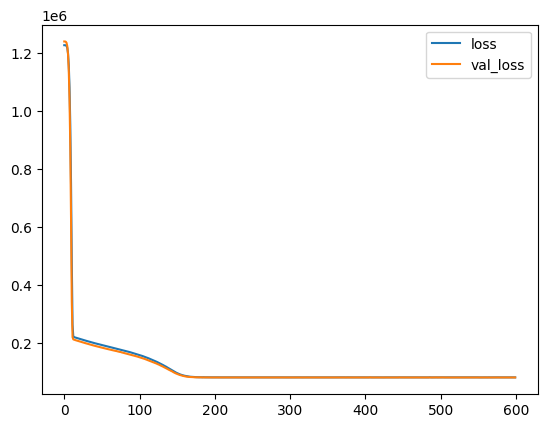
数据似乎与早停工和辍学相结合的数据不太合适:
model = Sequential()
model.add(Dense(10, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1))
early_stopping = EarlyStopping(monitor='val_loss', mode='min', patience=25)
model.compile(optimizer='adam', loss='mae')
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=600, callbacks=[early_stopping])
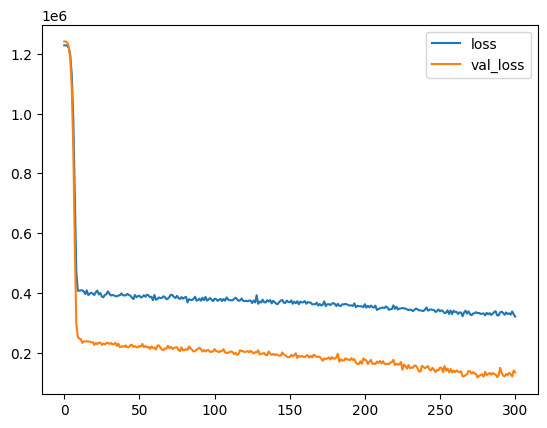
我想弄清楚为什么在结果如此之远的时候就会停止早停。我猜这个模型会持续到600个世纪结束,不过提前停止会在300个左右拉下插头。
我可能做错了什么,但我无法弄清楚,所以任何见解都会被感激。(预先谢谢:)
回答 2
Stack Overflow用户
发布于 2022-06-10 05:10:25
它定义了性能度量,并指定了是最大化还是最小化。
然后Keras在适当的时期停止训练。当指定verbose=1时,当培训在keras中停止时,可以在屏幕上输出。
es = EarlyStopping(monitor='val_loss', mode='min')
由于性能没有提高,立即停止可能是无效的。耐心定义了多少次允许不提高性能的时代。Partiance是一个相当主观的标准。根据所使用的数据和模型的设计,可以改变最优值。
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=50)
当模型选择早期停止对象停止训练时,状态通常会比以前的模型具有更高的验证错误。因此,可以控制模型的早期停止,使模型的验证误差不再通过在一定时间点停止模型的训练而降低,但停止状态并不是最好的模型。因此,有必要以最佳的验证性能来存储模型,为此,称为model检查点的对象存在于keras中。如果验证性能优于前一个时代,此对象将监视验证错误,并无条件地存储参数。通过此方法,当训练停止时,可以返回验证性能最高的模型。
from keras.callbacks import ModelCheckpoint
mc = ModelCheckpoint ('best_model.h5', monitor='val_loss', mode='min', save_best_only=True) 在回调参数中,允许存储最佳模型。
hist = model.fit(train_x, train_y, nb_epoch=10,
batch_size=10, verbose=2, validation_split=0.2,
callbacks=[early_stopping, mc]) 在您的情况下,Patience 25指示当参考值不连续提高25倍时是否结束。
from keras.callbacks import ModelCheckpoint
model = Sequential()
model.add(Dense(10, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1))
early_stopping = EarlyStopping(monitor='val_loss', mode='min', patience=25, verbose=1)
mc = ModelCheckpoint ('best_model.h5', monitor='val_loss', mode='min', save_best_only=True)
model.compile(optimizer='adam', loss='mae')
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=600, callbacks=[early_stopping, mc])Stack Overflow用户
发布于 2022-06-10 13:53:52
我推荐两件事。在早期停止回调中,设置参数
restore_best_weights=True这样,如果早期停止回调激活,您的模型将被设置为具有最低验证损失的时代的权重。为了获得更低的验证损失,我建议您使用回调ReduceLROnPlateau。我推荐的这些回调代码如下所示。
estop=tf.keras.callbacks.EarlyStopping( monitor="val_loss", patience=4,
verbose=1, estore_best_weights=True)
rlronp=tf.keras.callbacks.ReduceLROnPlateau(monitor="val_loss", factor=0.5,
patience=2, verbose=1)
callbacks=[estop, rlronp]在model.fit集合参数callbacks=callbacks中。将划时代设置为一个大数目,因此很可能会激活estop回调。
https://stackoverflow.com/questions/72568936
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号