
大熊猫指数拟合
我有这样的数据:
puf = pd.DataFrame({'id':[1,2,3,4,5,6,7,8],
'val':[850,1889,3289,6083,10349,17860,28180,41236]})数据似乎呈指数曲线。让我们看看情节:
puf.plot('id','val')
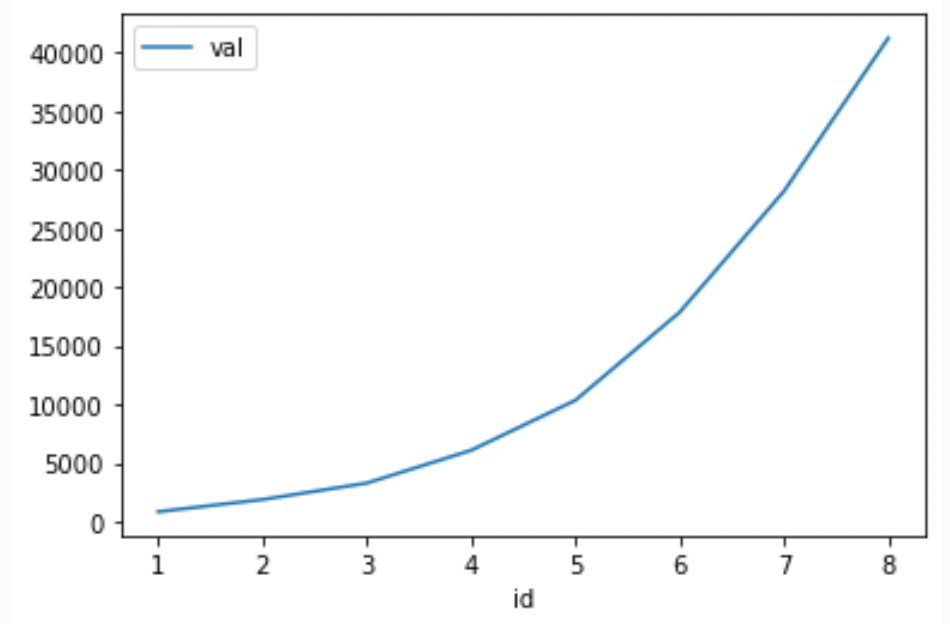
我想要拟合一个指数曲线($$ y = Ae^{Bx} $$,A乘以e到B*X),并将它作为一个列添加到Pandas中。首先,我尝试记录这些值:
puf['log_val'] = np.log(puf['val'])然后使用Numpy来拟合方程:
puf['fit'] = np.polyfit(puf['id'],puf['log_val'],1)但我发现了一个错误:
ValueError: Length of values (2) does not match length of index (8)我的预期结果是Pandas中新列的拟合值。我附上一幅图片,上面有我想要的列值(橙色):

我被困在这个密码里了。我不知道我做错了什么。我如何创建一个新的列与我的拟合值?
回答 2
Stack Overflow用户
发布于 2022-06-10 03:52:12
您将得到该错误,因为np.polyfit(puf['id'],puf['log_val'],1)返回两个值array([0.55110679, 6.39614819]),这不是数据的形状。
这就是你想要的
y = a* exp (b*x) -> ln(y)=ln(a)+bx
f = np.polyfit(df['id'], np.log(df['val']), 1)哪里
a = np.exp(f[1]) -> 599.5313046712091
b = f[0] -> 0.5511067934637022给予
puf['fit'] = a * np.exp(b * puf['id'])
id val fit
0 1 850 1040.290193
1 2 1889 1805.082864
2 3 3289 3132.130026
3 4 6083 5434.785677
4 5 10349 9430.290286
5 6 17860 16363.179739
6 7 28180 28392.938399
7 8 41236 49266.644002Stack Overflow用户
发布于 2022-06-10 04:35:26
请注意,您要求建立指数模型,但是您有对数线性模型的结果。
请看下面的工作:
对于对数线性,我们正在拟合E(log(Y))ie log(y) - (log(b[0]) +b[1]*x)。
from scipy.optimize import least_squares
least_squares(lambda b: np.log(puf['val']) -(np.log(b[0]) + b[1] * puf['id']),
[1,1])['x']
array([5.99531305e+02, 5.51106793e-01]) 这些是excel给出的值。
另一方面,为了拟合指数曲线,随机性是在Y上而不是在它的对数上,因此我们有:E(Y)=b[0]*exp(b[1] *x):
least_squares(lambda b: puf['val'] - b[0]*exp(b[1] * puf['id']), [0,1])['x']
array([1.08047304e+03, 4.58116127e-01]) # correct results for exponential fit取决于您的模型选择,值略有不同。
更好的模特?由于您有相同数量的参数,请考虑给出较低偏差或更好的样本预测值的参数。
请注意,理想的指数模型是E(Y) = A'B'^X,比较而言,它可以写成log(E(Y)) = A + XB,而对数线性模型则是E(log(Y) = A + XB。注意期望的差异。
我们有两种模式:
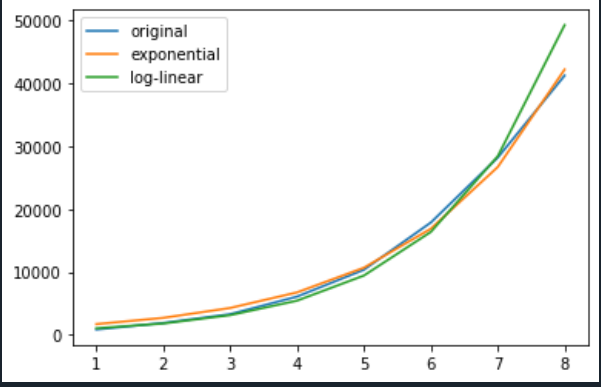
注意,当我们进入更高的数字时,对数线性高估。而在较低的数字中,指数过高。
图像代码:
from scipy.optimize import least_squares
log_lin = least_squares(lambda b: np.log(puf['val']) -(np.log(b[0]) + b[1] * puf['id']),
[1,1])['x']
expo = least_squares(lambda b: puf['val'] - b[0]*exp(b[1] * puf['id']), [0,1])['x']
exp_fun = lambda x: expo[0] * exp(expo[1]*x)
log_lin_fun = lambda x:log_lin[0] * exp(log_lin[1]*x)
plt.plot(puf.id, puf.val, label = 'original')
plt.plot(puf.id, exp_fun(puf.id), label='exponential')
plt.plot(puf.id, log_lin_fun(puf.id), label='log-linear')
plt.legend()https://stackoverflow.com/questions/72568869
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号