
阿拉伯语pdf文本提取
我试图从阿拉伯pdfs中提取文本- -原始数据提取,而不是OCR -。
我尝试过许多包、工具,但它们都不起作用,python包、pdfBox、adobe和许多其他工具以及所有这些工具和字段都可以正确提取文本,要么它读取文本LTR,要么它做错误的解码。
以下是来自不同工具的两个示例
样本1:
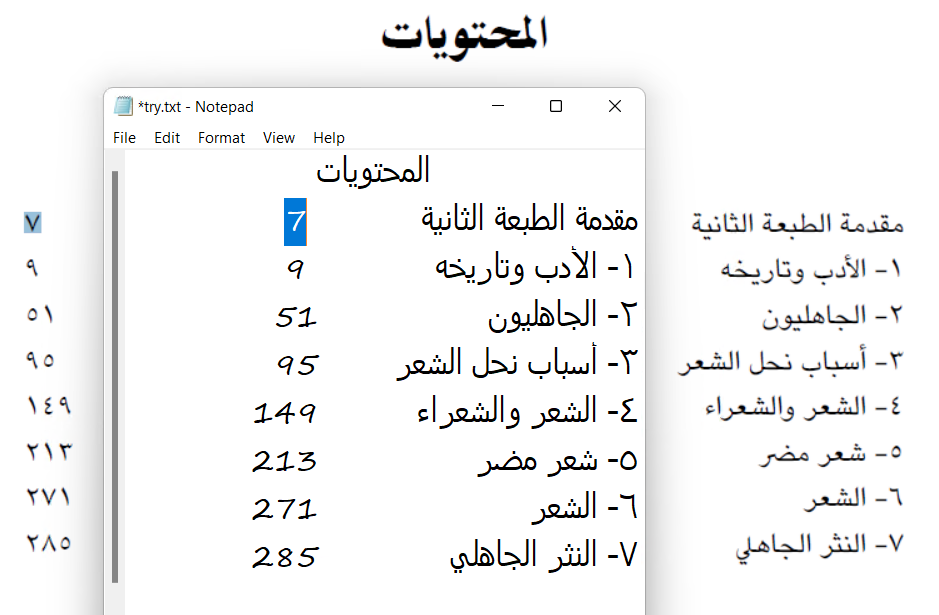
املحتويات
7 الثانية الطبعة مقدمة
9 وتاريخه األدب -١
51 الجاهليون -٢
95 الشعر نحل أسباب -٣
149 والشعراء الشعر -٤
213 مرض شعر -٥
271 الشعر -٦
285 الجاهيل النثر -٧样本2:
ﺔﻴﻧﺎﺜﻟا ﺔﻌﺒﻄﻟا ﺔﻣﺪﻘﻣ
ﻪﺨﻳرﺎﺗو بدﻷا -١
نﻮﻴﻠﻫﺎﺠﻟا -٢
ﺮﻌﺸﻟا ﻞﺤﻧ بﺎﺒﺳأ -٣
ءاﺮﻌﺸﻟاو ﺮﻌﺸﻟا -٤
ﴬﻣ ﺮﻌﺷ -٥
ﺮﻌﺸﻟا -٦
ﲇﻫﺎﺠﻟا ﺮﺜﻨﻟا -٧原文

是的,我可以复制它,得到同样的渲染文本。
有什么工具可以正确提取阿拉伯文本吗?
书的链接可以找到这里
回答 2
Stack Overflow用户
发布于 2022-06-09 14:59:21
PDF中的文本与用于构造它的文本不一样,在您的示例中,页面7在表面以阿拉伯语显示,但在纯文本中编码为7。
然而,更大的问题是字体所支持的语言,因此在记事本中,我不得不接受脚本字体来查看相似之处,但这就是使用字体替换。
另一个复杂的问题是Unicode和空格排序。
所以结果是
pdftotext -f 5 -l 5 في_الأدب_الجاهلي.pdf try.txt充其量看起来就像
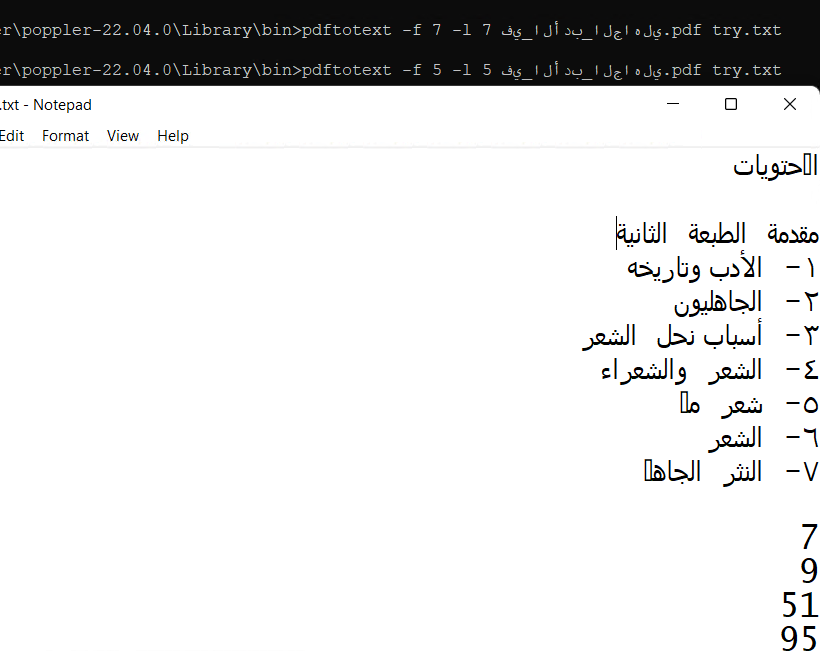
因此,概括地说,与任何其他简单尝试相比,示例1即使不是更好,也是相等的.。
我找到了一种解决这个问题的方法,在提取文本之后,打开txt文件并使用提供 unicodedata.normalize() 函数的unicodedata模块对其内容进行规范化。因此,我现在可以说pdftotext是阿拉伯文本提取的最佳工具。
Stack Overflow用户
发布于 2022-10-03 08:58:15
Unicode规范化应该解决这个问题。(您可以选择NFKC)
大多数编程语言都是正常的。有关正常化的更多信息,请在这里查看。https://unicode.org/reports/tr15/
https://stackoverflow.com/questions/72559699
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号