
使用it.chain的迭代
使用it.chain的迭代
提问于 2022-06-06 16:40:25
我不得不返回函数的结果,它检查样本进行A/B测试,并给出了结果。计算是正确的,但不知何故,我得到了两次结果。下面的代码和输出。
def test (sample1, sample2):
for i in it.chain (range(len(sample1)), range(len(sample2))):
alpha = .05
difference = (sample1['step_conversion'][i] - sample2['step_conversion'][i])/100
if (i > 0):
p_combined = (sample1['unq_user'][i] + sample2['unq_user'][i]) / (sample1['unq_user'][i-1] + sample2['unq_user'][i-1])
z_value = difference / mth.sqrt(
p_combined * (1 - p_combined) * (1 / sample1['unq_user'][i-1] + 1 / sample2['unq_user'][i-1]))
distr = st.norm(0, 1)
p_value = (1 - distr.cdf(abs(z_value))) * 2
print( sample1['event_name'][i], 'p-value: ', p_value)
if p_value < alpha:
print('Deny H0')
else:
print('Accept H0')
return 因此,我只需要输出一次结果(在框中标记),但我从两个示例中获得了两次结果。
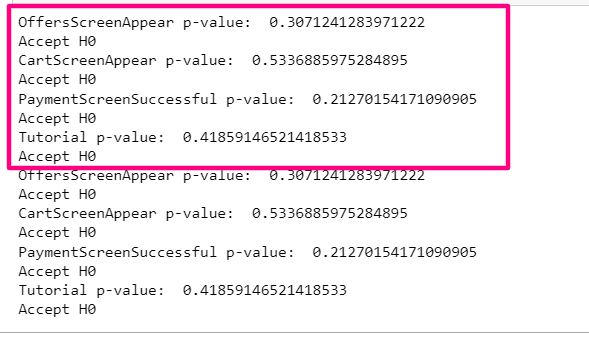
回答 1
Stack Overflow用户
发布于 2022-06-06 16:57:45
在使用时,您应该避免使用大多数for循环,并使用标准的矢量化方法。在适用的情况下使用NumPy。
首先,我重新设置了数据格式的索引(索引),以确保.loc可以与标准的数字索引一起使用。
sample1 = sample1.reset_index()
sample2 = sample2.reset_index()下面是我认为循环所做的事情。我无法测试它,如果没有清晰的描述、示例数据和预期的结果,任何人都会猜测下面的代码是否能满足您的需要。但它可能会变得更加接近,并且主要作为矢量化方法的一个例子。
import numpy as np
difference = (sample1['step_conversion'] - sample2['step_conversion']) / 100
n = len(sample1)
# Note that Pandas uses `n` as the highest *valid* index when using `.loc`, `n-1` is one lower
p_combined = ((sample1.loc[1:, 'unq_user'] + sample2.loc[1:, 'unq_user']).reset_index(drop=True) /
(sample1.loc[:n-1, 'unq_user'] + sample2.loc[:n-1, 'unq_user'])).reset_index(drop=True)
z_value = difference / np.sqrt(
p_combined * (1 - p_combined) * (
1 / sample1.loc[:n-1, 'unq_user'] + 1 / sample2.loc[:n-1, 'unq_user']))
distr = st.norm(0, 1) # ??
p_value = (1 - distr.cdf(np.abs(z_value))) * 2
sample1['p_value'] = p_value
print(sample1)
# The below prints a list of True values for elements for which the condition is valid.
# You can also use e.g. `print(sample1[p_value < alpha])`.
alpha = 0.05
print('Deny H0:')
print(p_value < alpha)
print('Accept H0:')
print(p_value > alpha)不需要循环,对于一个大的数据帧,上面的速度要快得多。
请注意,.reset_index(drop=True)有点难看。但如果不是这样的话,潘达斯将把这两个数据除以相等的指数,这不是我们想要的。这样,就可以避免这种情况。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72520845
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号