
组合假人和计算熊猫数据
我有这样一只熊猫:
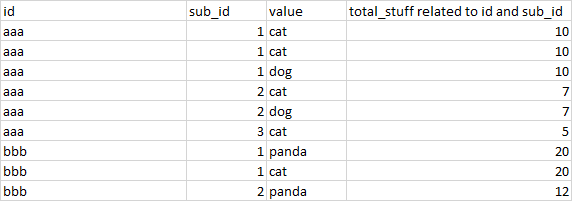
作为一个纯文本:
{'id;sub_id;value;total_stuff相关id和sub‘:'aaa;1;cat;10','aaa;1;cat;10',’aaa;1;狗;10‘,'aaa;2;cat;7',aaa;2;狗;7’,‘aaa;2;狗;7’,'aaa;3;cat;5',血脑b;1;熊猫;20‘,’血脑屏障;1;cat;20‘,’血bbb;2;熊猫;12‘}
我想要的输出是这个。
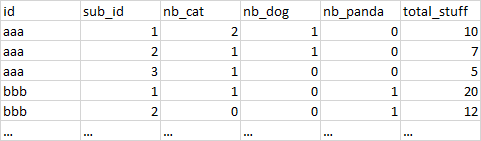
请注意,有许多不同的“值”可能,所以我需要自动化创建虚拟变量(nb_animals)。但是这些虚拟变量必须包含id和sub_id出现的次数。对于给定的id/sub_id组合,total_stuff总是相同的值。
我试过使用get_dummies(df, columns = ['value']),它给了我这张桌子。
{kind=link}
作为一个纯文本:
{'id;sub_id;value_cat;value_dog;value_panda;total_stuff:'aaa;1;2;1;0;10','aaa;2;1;1;0;7',‘aaa;2;1;1;0;7’aaa;2;1;1;0;7 'aaa;3;1;0;0;5',‘bbb;1;1;1;0;1;20','bbb;1;1;0;1;20','bbb;2;0;0;1;12'}
我很想使用某种df.groupby(['id','sub_id']).agg({'value_cat':'sum', 'value_dog':'sum', ... , 'total_stuff':'mean'}),但是编写所有可能的动物价值都太乏味了。
那么,如何获得适当的值聚合计数/和,以及total_stuff的平均值(因为total_stuff在id/sub_id组合中是唯一的)
谢谢
编辑:谢谢齐基奇给出了简洁的回答。agg_dict是我所需要的
回答 1
Stack Overflow用户
发布于 2022-06-06 10:00:07
使用pd.get_dummies转换分类数据
df = pd.get_dummies(df, prefix='nb', columns='value')然后按id和subid分组
agg_dict = {key: 'sum' for key in df.columns if key[:3] == 'nb_'}
agg_dict['total_stuff'] = 'mean'
df = df.groupby(['id', 'subid']).agg(agg_dict).reset_index()https://stackoverflow.com/questions/72515170
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号