
如何通过索引中的唯一值将总结的Python表拆分成图表、图表或更个性化的表?
如何通过索引中的唯一值将总结的Python表拆分成图表、图表或更个性化的表?
提问于 2022-06-02 17:51:21
我一直在努力寻找一种对我想要的有用的方法,但是运气不太好。我有一个大型数据文件,其中包含关于不同类型文档状态的信息。
我从这种形式开始:
import pandas as pd
import numpy as np
import random
list = ['Up to Date', 'Expiring Soon', 'Expired']
y = pd.DataFrame(np.random.choice(list, size=(60,6)))
y我创建了几个数据表,通过以下方法对信息进行分组:
a = z.groupby('Primary staff')['A Status'].value_counts()
b = z.groupby('Primary staff')['B Status'].value_counts() etc..然后,我将所有创建的表连接在一起,从而得到一个可接受的表,该表如下所示:
Primary staff | A | B | C | D | E |
Bob Expired | 3 | 2 | 0 | 0 | 1 |
Expiring Soon | 10| 9 | 6 | 7 | 2 |
Up to Date | 45| 39| 61| 64| 69|
Sally Expired | 1 | 7 | 4 | 0 | 3 |
Expiring Soon | 9 | 13| 6 | 2 | 1 |
Up to Date | 35| 61| 28| 33| 70| etc.....我想按基层员工分类,但在本表中,基层员工不再是一栏,而是多索引的一部分。理想情况下,这将成为一个分组条形图或类似于每个主要工作人员的类型,将文档名称保存在x轴上,并在y轴上进行计数。有什么建议吗?要么是员工有自己的工作表,要么是如下所示的图表(请原谅我糟糕的Microsoft绘图技能):
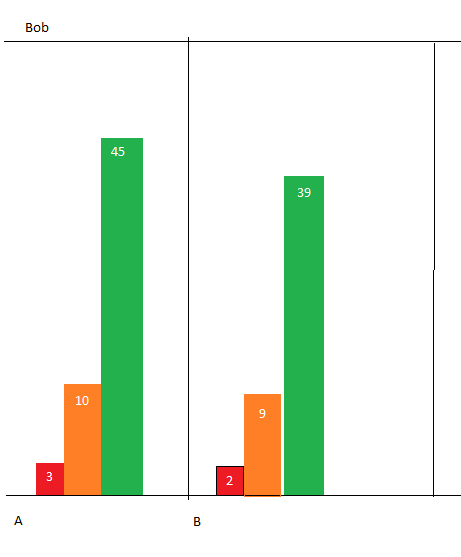
这将需要为每个主要的工作人员,包括像图例,y轴,等等。
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-06-03 22:41:12
我拿了你的“可接受的桌子”做了熊猫融化。
import pandas as pd
import hvplot.pandas # noqa
pd.options.plotting.backend = 'holoviews'
df = pd.DataFrame({'Primary staff': {0: 'Bob',
1: 'Bob',
2: 'Bob',
3: 'Sally',
4: 'Sally',
5: 'Sally'},
'Status': {0: ' Expired ',
1: ' Expiring Soon',
2: ' Up to Date',
3: ' Expired ',
4: ' Expiring Soon',
5: ' Up to Date'},
'A': {0: 3, 1: 10, 2: 45, 3: 1, 4: 9, 5: 35},
'B': {0: 2, 1: 9, 2: 39, 3: 7, 4: 13, 5: 61},
'C': {0: 0, 1: 6, 2: 61, 3: 4, 4: 6, 5: 28},
'D': {0: 0, 1: 7, 2: 64, 3: 0, 4: 2, 5: 33},
'E': {0: 1, 1: 2, 2: 69, 3: 3, 4: 1, 5: 70}})然后,使用pd.melt:
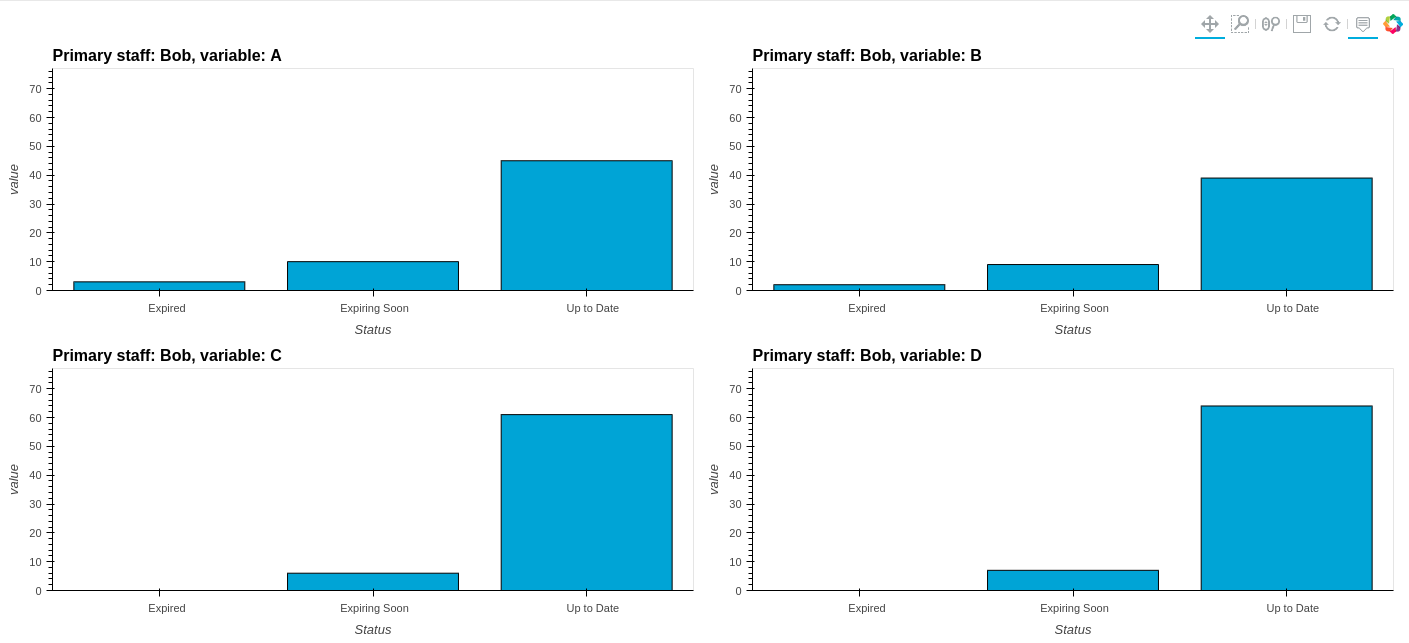
new_df = pd.melt(
df, id_vars=["Primary staff", "Status"], value_vars=["A", "B", "C", "D", "E"])最后,使用hvplot
new_df.hvplot.bar(
x="Status", stacked=False, by=["Primary staff","variable"], subplots=True).cols(2)这将返回每个Primary staff和Status值的条形图,同时还具有与绘图具有交互性的优点。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72480378
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号